配套软件版本:V10及更高 数据管家——增强版网络爬虫 老版本对应教程:V9及更低 集搜客网络爬虫 的对应教程是《集搜客网络爬虫的核心名词》 集搜客网络爬虫的操作方法很直观,想要什么,就把他们标记出来,网络爬虫就会自动把他们爬下来。标记过程很自由,不讲究顺序。 1. 直观标注 用爬虫软件的浏览器加载网页,在网页上,看到想采集的内容,点击两次,就弹出一个标签,给标签起个名字。把所有要采集的内容逐个这样标注。不分先后顺序。
然后,爬虫软件把标注的内容采集下来,放在一个excel表格里,类似下表。标签名就是excel表格的表头字段(注意,这只是采集了一个公司网页,实际采集中,爬虫要采集很多类似的公司网页,数据会有很多行)。
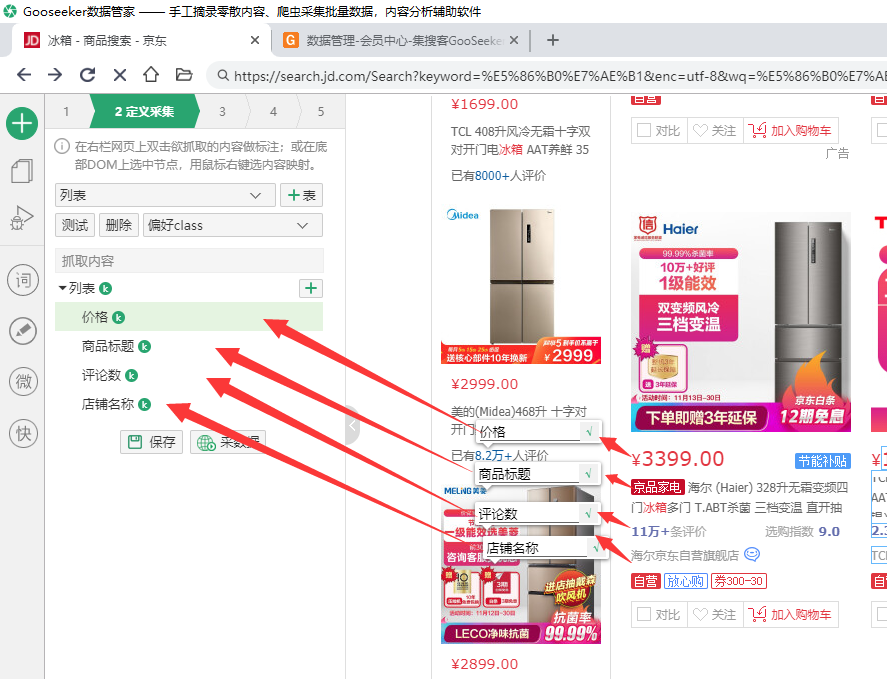
2. 任务 在一个网页做完了标注,并按爬虫软件的提示,保存下来,我们就建立了一个爬虫任务(采集任务)。以后可以运行这个任务爬数据,还可以编辑修改这个任务。 3. 整理箱 在一个爬虫任务里,被标注的内容放在一个整理箱里,整理箱对应爬虫输出的excel表格。下图红框里是一个整理箱,显示在爬虫界面左边的一个工作台上。为什么要引入整理箱这个概念?因为我们往往会对一批标注内容做一些操作,有了整理箱的概念,比较方便。而且,整理箱也凸显了集搜客爬虫的操作特点:在网页上用鼠标点一点,就把要抓取的内容放到一个箱子里。
4. 映射 “映射”这个词经常出现,表示:“把网页上的内容与整理箱中的标签建立联系”(也就是网页上的内容与excel表格的字段建立关系)。标注过程就是建立映射关系,有了这个关系,网络爬虫就知道从哪里采集数据并存储到哪里。
开始阅读《从入门到精通》 |