配套软件版本:V10及更高 数据管家——增强版网络爬虫 老版本对应教程:V9及更低 集搜客网络爬虫 的对应教程是《连续动作:采集悬浮窗信息——以微博为例》 鼠标悬停后,浮窗里显示的信息,如何采集?需要用连续动作中的悬浮动作。下面以淘宝关键词搜索店铺为例,演示如何采集浮窗里显示的店铺动态评分。
案例: 第一级任务:悬停信息采集-第一级(可点击下载) 第二级任务:悬停信息采集-第二级(可点击下载) 样本网址:https://shopsearch.taobao.com/search?q=%E6%96%87%E5%85%B7 采集内容:店名、卖家、地址、描述相符、服务态度、物流服务 1. 定义第一级任务 第一级规则主要是为了设置悬浮动作。所以我们只在第一级规则里采集一个字段。 1.1 打开网页,进入任务定义状态
1.2 在第一个店铺标注一个要采集的字段 本例中,在第一个店铺,标注了店名。具体的标注操作可以参考《采集网页数据》。
上面的操作中,为了提高任务的适应性,给店铺列表和店名都做了定位标志映射。 1.3 翻页设置 用文具搜索出来的店铺有很多页,所以还要做翻页。参考翻页采集。 1.4 设置悬浮动作 到工作台4,新建一个动作。 动作后执行的任务是悬停信息采集-第二级,把这个名字记下来,这是第二级任务的名字。
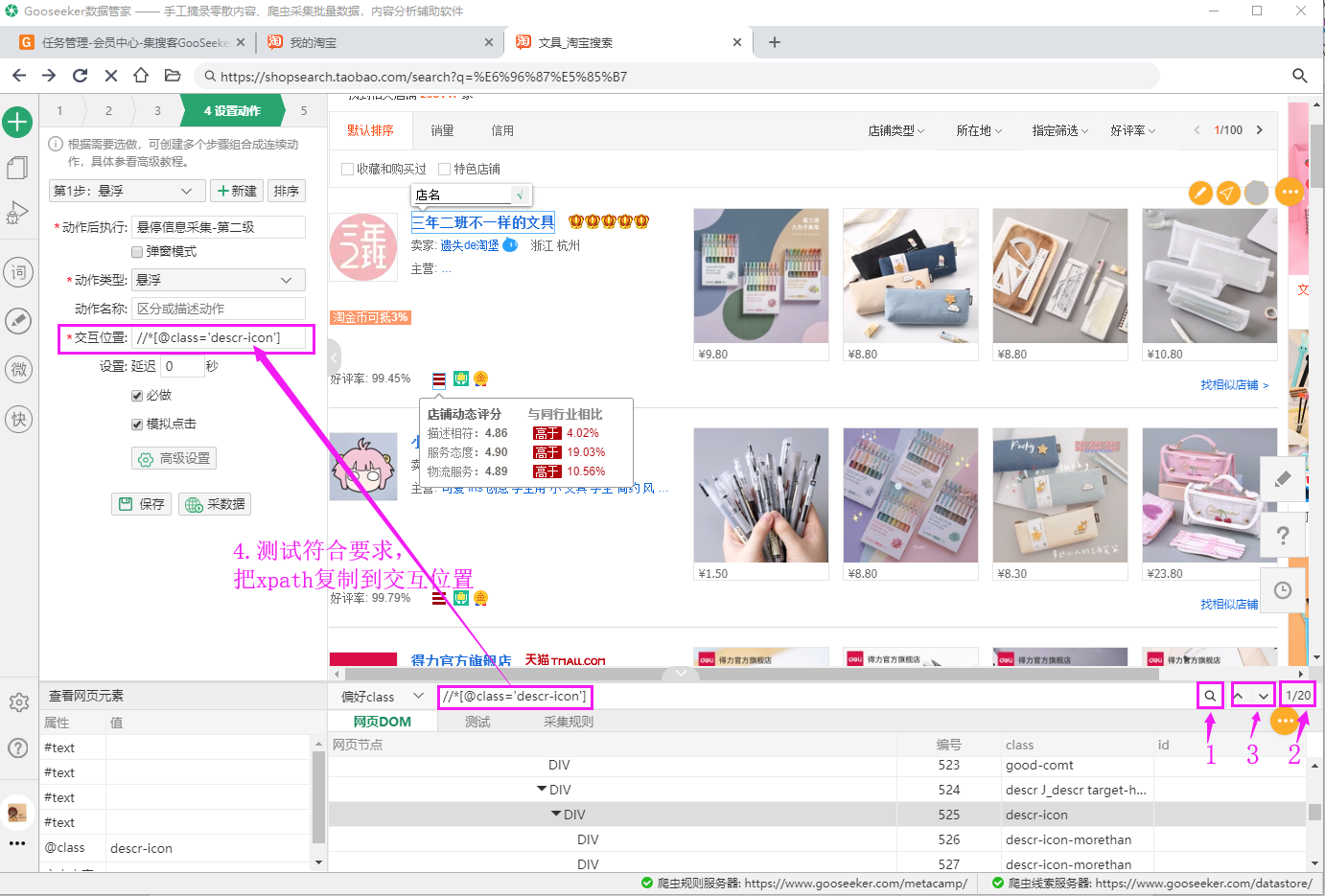
下面,我们来详细讲解怎么找到交互位置的xpath。 什么是交互位置?鼠标放在这个位置,会出现悬浮窗。如下图所示。 点击这个位置,光标对应到下面的DOM节点。 然后点击生成xpath。  这个DOM节点有比较特殊的class值,所以定位偏好class。 生成xpath,并用搜索和上下箭头,检测这个xpath是符合要求。 这个网页上,有20个店铺,应该有20个悬浮位置,点击搜索按钮,搜到了20个位置,点击上下箭头,看到光标定位到一个个悬浮位置。所以这个xpath满足要求。把它复制到工作台的交互位置。
至此,悬浮动作设置完成,点击工作台2上的保存,保存任务。另外,还设置了一个延迟时间,表示悬浮窗出现后,过3s再开始采集数据。
2. 退出第一级任务定义状态 第一级任务定义已经完成了。在开始定义第二级任务之前,先要从第一级任务中退出来。 退出按钮在网页浏览窗口的左上方。
3. 设置第二级任务 3.1 进入第二级任务定义状态 第二级任务仍旧在原来的网页上做采集规则,所以直接点击+号,进入第二级任务定义。 在第一级任务已经设置了第二级任务的名字:悬停信息采集-第二级,把它填写在任务名栏。
3.2 冻结页面 现在,需要把悬停信息冻结住,才能进行字段标注。 悬停信息出来后,按Alt和箭头键,选择冻结页面按钮,保持Alt,回车确认。
3.3 对第一个店铺做字段标注 具体的标注操作,参见《采集网页数据》。
3.4 对整理箱节点做定位映射 如上图中的步骤3,右击LI节点,选择定位映射给店铺。 这种操作,是定位映射采集列表(也可以用另外一张采集列表的方法:样例复制),告诉爬虫,像第一个店铺采集的字段一样,采集各个店铺的数据 。 之所以选中LI节点,因为每个LI节点完整包含一个店铺,而且具有相同的class属性(list-item)。
3.5 测试保存
4. 启动采集 因为第一级任务和第二级任务是用悬浮动作联系起来的,所以只运行第一级任务就可以了,第二级任务会自动执行。详细操作可以参考教程《启动采集》 4.1 任务管理页面
4.2 启动第一级任务 这个网页只有一条线索(即待采集网址;所有的翻页算一条线索),所以线索数是1。有100页,如果想要快点看到采集结果,可以限制翻页次数。
确定后,爬虫会弹出一个新的窗口,网页加载出来,悬停信息一个个出现,采集进行中,在采集窗口的右下角有绿色的状态球。
5. 下载数据 采集完成后,在采集窗口,按提示导出excel,然后到数据管理页面下载数据。 本例采集到的数据截图如下:
上篇文章:《自动滚屏采集瀑布流网页-以今日头条新闻为例》 下篇文章:《自动选择下拉菜单采集数据—以知网为例》 |