配套软件版本:V10及更高 数据管家——增强版网络爬虫 老版本对应教程:V9及更低 集搜客网络爬虫 的对应教程是《连续动作:设置自动返回上级页面》 当网页上的超链接没有独立网址,而是一段JavaScript代码,比如:onclick=”javascript:void(0)”,点击超链接后,当前网页会切换成新网页的信息。这种情况下,只能用连续动作的点击动作,进入超链接网页里采集信息,然后用回退动作,返回到原来的页面,继续点击下一个超链接。 注意:对于具有独立网址的超链接,做层级采集是最简单的方法。如果没有独立网址,并且点击超链接,弹出新的页签窗口,原来的网页还在,这种情况下要用飞掠模式。 下面就以懂车帝为例,讲解从车型列表页依次进入各车型页面,抓取车子的数据。 案例 第一级任务:回退教程-懂车帝-第一级 (可点击下载) 第二级任务:回退教程-懂车帝-第二级 (可点击下载) 样本网址:https://m.dcdapp.com/motor/m/car_series/list?brand_id=2&show_city_button= 第一级采集内容:车名、报价、指导价 第二级采集内容:车名、参数、全国价、价格区间、车型、销售商价格、官方指导价 1. 定义第一级任务 1.1 打开网页,进入任务定义状态
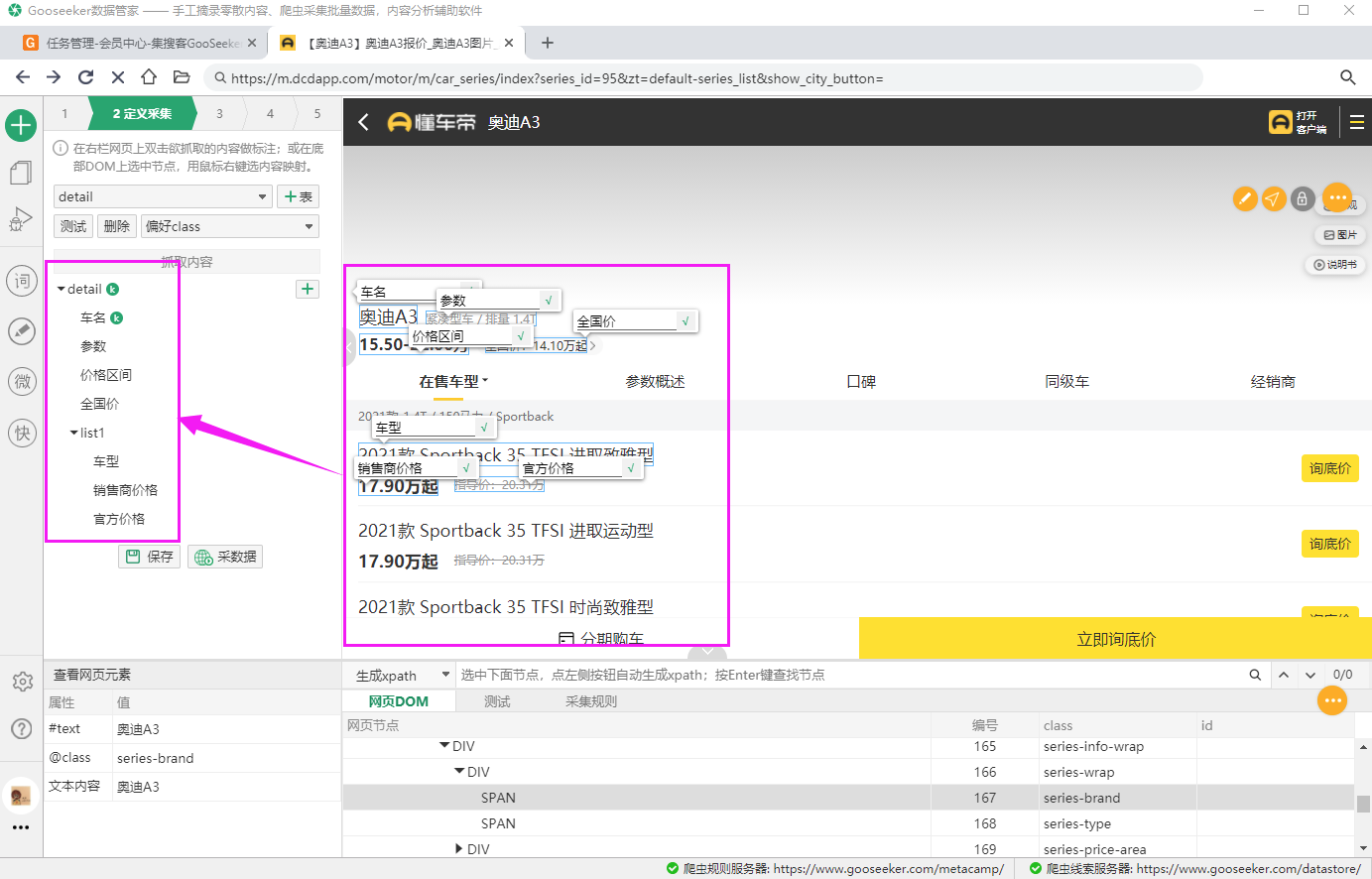
1.2 标注字段 对第一个车标注要抓取的字段,具体的标注操作见《采集网页数据》。
1.3 样例复制 要抓取网页上所有车的信息,需要做样例复制。或者对整理箱节点做定位。可以参见前面的教程。 1.4 设置点击动作 1.4.1 进入动作台4,点击新建 选择点击动作。 做了点击后,到了新的页面,要执行的任务名:回退教程-懂车帝-第二级 这个任务名要记下来,后面做第二级任务的时候要用到。
1.4.2 交互位置的xpath 交互位置,就是点击哪个位置,会进入新的页面。本例中,点击车子的图片,会进入新的页面。 怎么找图片的xpath? 点击车子的图片,光标对应到下面的DOM节点。这个节点有比较特殊的class值,生成xpath时,选择偏好class。
xpath生成后,要搜索一下这个xpath,是否对应到所有的车子图片。这个页面上有32个车,所以搜索出的位置数应该是32。再点击上下箭头,看看是否对应到每辆车的图片。
经过上面的检验,这个xpath是正确的,把它复制拷贝到交互位置。延迟5秒。表示做完点击后,等待5秒,爬虫再开始采集。
1.5 测试保存第一级任务 转到工作台2,测试任务,没有问题,保存。现在不要采集,因为第二级任务还没有设置。
2. 退出第一级任务 第一级任务设置完成后,在设置第二级任务之前,先退出第一级任务。 橙色的退出按钮在页面右上方。
3. 定义第二级任务 3.1 跳转到新的网页,进入任务定义状态 点击第一个车,跳转到新的页面。然后进入任务定义状态。
3.2 字段标注和样例复制 在这个网页上标注要采集的字段,做样例复制。这里限于篇幅,就不讲解了。
3.3 设置回退动作 采集完这个车之后,需要再回到原来的页面,继续点击下一个车,到下一个车的页面去采集数据。 所以需要一个回退动作,回退到原来的页面。 到工作台4,建立回退动作。步骤如下图所示。注意,回退动作后,回到原来的页面,执行原来的第一级任务。
3.4 测试保存第二级任务 到工作台2,测试第二级任务,没有问题,保存。
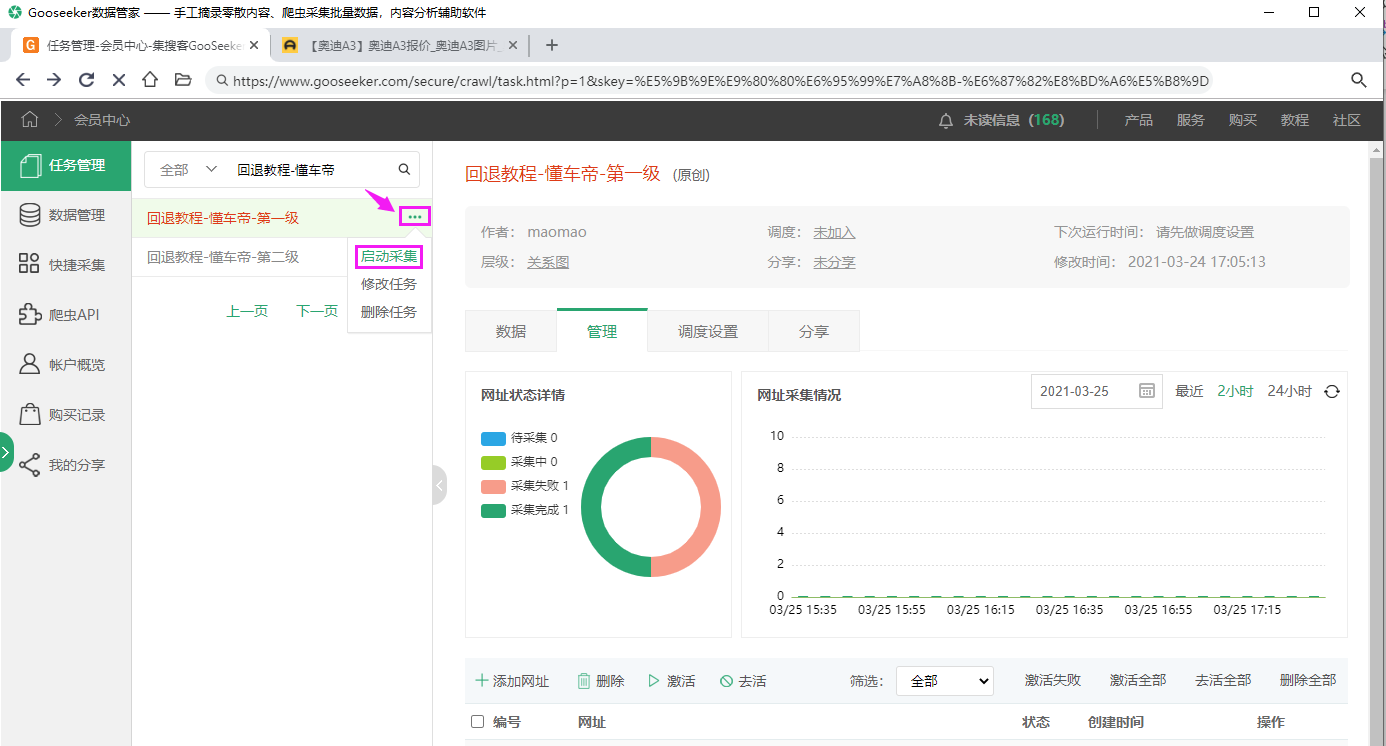
4. 启动采集 点击左侧栏的任务管理按钮,到任务管理页面,启动第一级任务,第二级任务会自动执行。
第一级任务的待采集网址是1,线索数是1。
然后,爬虫窗口弹出来,网页在列表页和各个车型的网页来回切换,采集数据。采集完成后,按提示,导出excel数据。 采集到的第二级任务的示例数据:
上篇文章:《自动选择下拉菜单采集数据-以知网为例》 下篇文章:《自动滚屏采集瀑布流网页-以今日头条新闻为例》 |