1. 问题 用作测试的爬虫任务:B站评论列表采集测试 B站上的用户评论内容放在一个多层嵌套的网页片段(HTML新技术)中,在定义规则模式下,如果点击用户评论中的任何信息,比如,某条评论的发布日期,只能定位到最外层网页片段,内部的内容一开始是生成不了DOM树的,所以就没法定位到具体的内容节点。如下图:
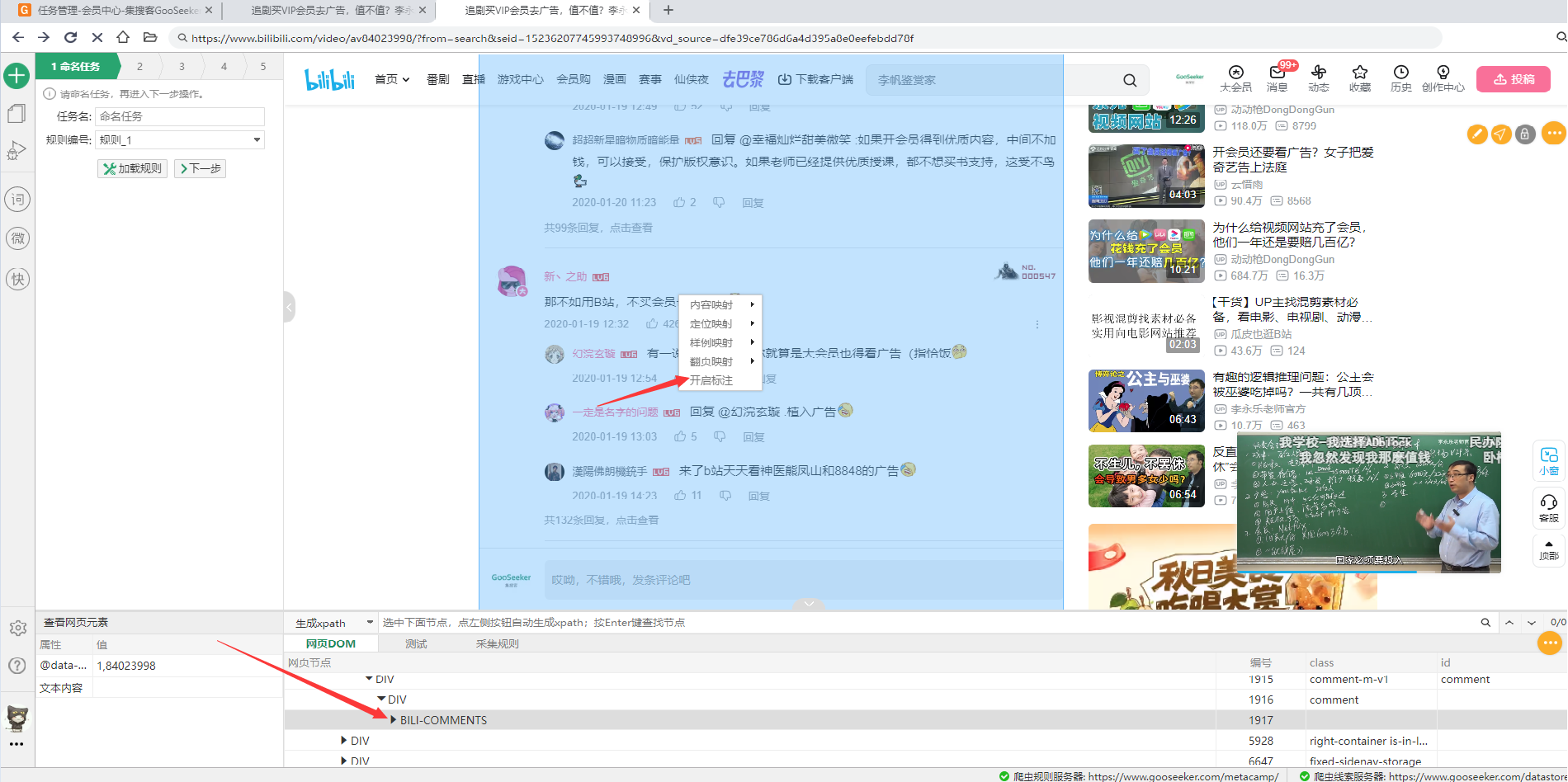
从V12.3.0版本开始,我们将逐步解决这个问题,实现定位到网页片段内部,并能为内部节点生成path,并根据path搜索网页上的节点。 2. 直观定位 首先要设法能够定位到网页片段内部。如下图,在代表网页片段的网页区域选择右键鼠标菜单“开启标注”,就能允许定位到网页片段内部。这个操作也可以在DOM树上做,选择代表网页片段的那个DOM节点,同样使用鼠标右键菜单“开启标注”。
开启以后,再把鼠标移动用户评论区域,就会发现蓝色背景覆盖的区域变小了,不再是整个评论区,而是具体某个人的评论。如下图:
如果在浏览器上点击那个区域,在DOM树上就能定位到网页片段内部代表这个用户区域的DOM节点。 B站用户评论区有大量的嵌套网页片段,如果想精确定位到某个用户发表评论的时间,需要执行多层“开启标注”,才能把发表时间、点赞数等等细粒度的内容剥出来。 3. 生成path 自定义path的含义扩展了,以前版本自定义的只有xpath,从V12.3.0版本开始,自定义path包括xpath和css选择器。 以前版本的path是扩展了的xpath,即使用<context></context>标签括起来的xpath定位iframe的位置,然后用最前面的没有括起来的部分定位到iframe内的DOM元素。 从V12.3.0开始,如果要采集网页片段内的内容,需要将xpath替换成扩展了的css选择器。所谓“扩展”,就是在普通的css选择器中增加<gs_root></gs_root>标签括起来的css选择器。在<gs_root></gs_root>内部的css选择器可以定位到一个网页片段整体,没有被<gs_root></gs_root>括起来的css选择器可以定位到一个DOM元素。
例如:上图的发布日期的css选择器是
定位DOM元素的时候从左到右一层层进入多级网页片段,最后用div#pubdate定位到最内层网页片段中的发布日期。 4. 直观标注和自定义xpath的变化 目前,针对网页片段内的内容,只能使用自定义path定义采集规则,不能通过内容映射或直观标注定义采集规则。 如果想采集网页片段内的内容,将整个网页片段映射给抓取内容,而不能将网页片段内的网页内容映射给抓取内容。 然后给抓取内容自定义xpath,而且选择专用定位模式,定位path只需要输入一个点号,内容path使用生成的css选择器。 如果是嵌套整理箱,跟xpath类似,css选择器应该也是相对的,即抓取内容的path相对于容器的path,不能使用完整的从html顶层节点开始定位的path。 5. 自定义path 假设我们要采集评论以及评论的回复,需要定义一个嵌套的整理箱,如下图。
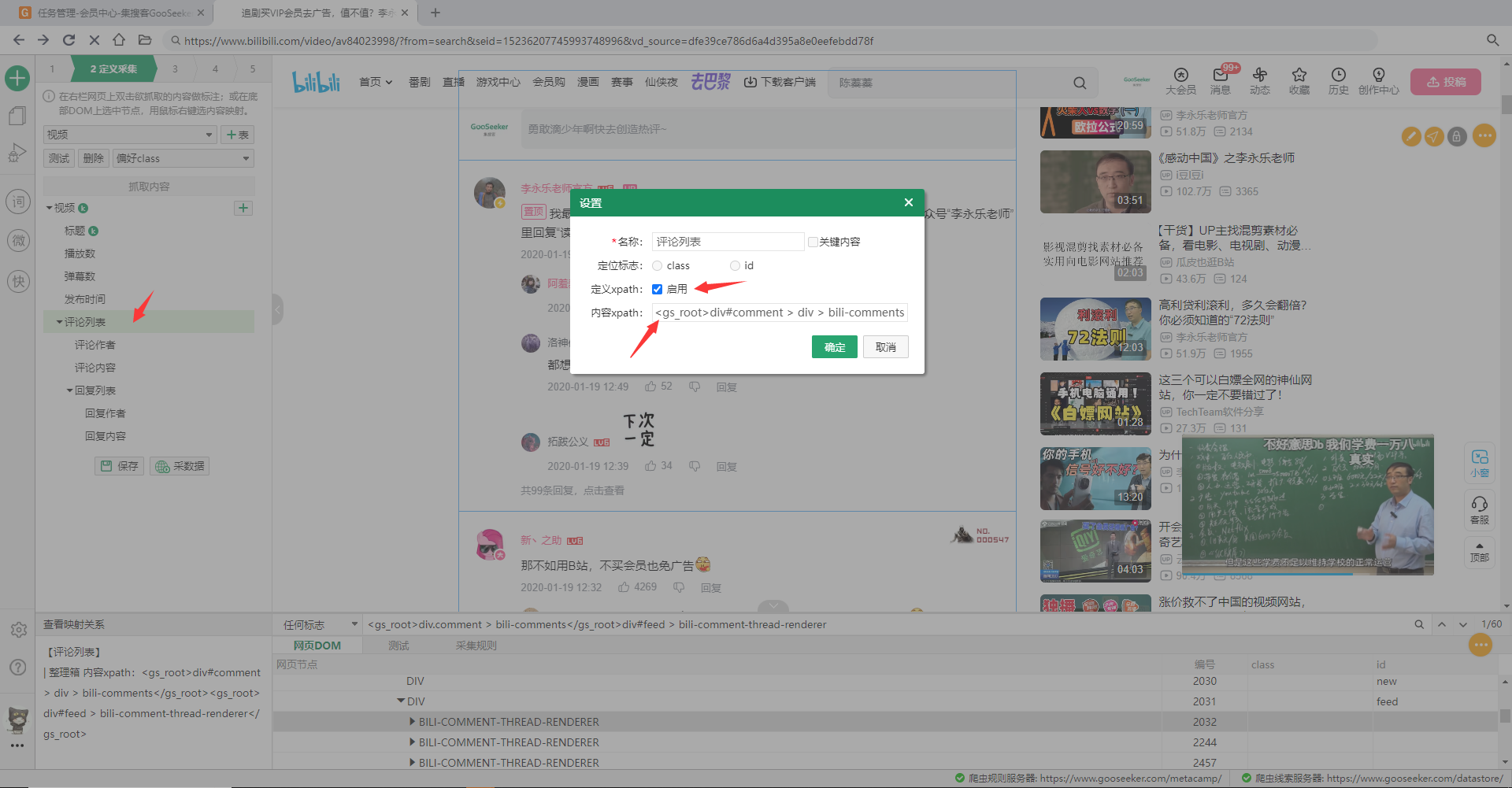
“评论列表”应该对应到多条评论,内部的“回复列表”应该为每条评论对应到多条的回复。他们都是容器节点,其包含的“评论作者”,“评论内容”,“回复作者”,“回复内容”才是要采集的内容,应该对应到具体的网页内容。 5.1 内容映射阶段 对于普通网页,只需要为采集内容做内容映射或者直观标注就行,此案例的采集内容有:“评价作者”、“评价内容”、“回复作者”,“回复内容”四个。 对于网页片段内的内容采集,我们不能直接做内容映射,否则既采集不到内容,还在以后加载分析规则的时候加载失败。所以,我们要对这四个抓取内容做特殊的映射。如上图,都用整个网页片段对应的那个DOM节点做内容映射。也就是说,只能用网页片段内部的DOM节点做内容映射。 做完内容映射以后,点击测试按钮,可以看到其他内容都采集到了,但是,评论列表容器内的所有内容都没有采集到。 下面就要为他们自定义path。 5.2 自定义path阶段 我们首先为“评论列表”自定义path(也就是css选择器)定位到多条评论,然后再为内部的“评论作者”自定义相对于“评论列表”的定位path。其他抓取内容和内部嵌套的整理箱也是用类似方法得到的定位path。 利用前面第三章讲的方法,为整理箱中的“评论列表”、“评价作者”、“评价内容”、“回复列表”、“回复作者”,“回复内容”都自定义path。 5.2.1 评论列表的path 如下图,先为评论列表生成path。
此前已经为网页片段开启了标注,鼠标浮到第一条评论区域(上图红框内),点击鼠标,可以看到下面DOM树定位到一个DOM节点。选择“任何标志”,生成css选择器path。为了验证这个path是正确的,可以点击右边放大镜图标,将会显示搜索到多少条评论。 把这个生成的path拷贝下来,双击整理箱中的“评论列表”,开启自定义path,输入进去。因为“评论列表”是一个容器,而不是普通的抓取内容,所以自定义path不需要选择兼用定位还是专用定位。
生成的path是:
注意要做手工修改:这里需要为生成的path做一点手工修改,如下,为最后一段path也套上<gs_root></gs_root>:
并不是每次都需要加上<gs_root></gs_root>,加上这个标签是告诉爬虫:为“评论列表”定位到的DOM节点不是普通的元素,而是一个网页片段,“评论列表”内的“评论作者”等抓取内容要在这个网页片段内部采集数据。相反,如果不是在网页片段内部采集数据,而是在一个普通html元素内部采集数据,就不用加<gs_root></gs_root>。 注意:优先使用“任何标志”,对于css选择器来说,这种类型最适合。 5.2.2 评论作者的path 这个网页有很多层网页片段,经过一系列开启标注以后,终于可以精确选中评论作者这个网页区域了,点击“任何标志”,生成path。如下图,蓝框刚好套在评论作者上,说明这里是最精准的。
把生成的path拷贝出来,如下:
这个path不能直接设置给“评论作者”,因为要变成相对于“评论列表”的path。 那么,把评论列表的path也拷贝过来比较一下:
可以看到,前面部分是相同的,只需要截掉前面相同的部分,保留以下部分:
把截取留下来的path部分输入到上图的“内容xpath”那里,而定位xpath那里输入了.号。这个.号是怎么来的?这是来自爬虫自动生成的采集规则。如下图:
我们点击测试按钮,切换到“采集规则”那里,看到为评论作者自动生成的规则那里就是一个.号,把这个部分拷贝过来作为定位xpath就对了。定位xpath是在加载分析规则的时候使用,并不在采集内容的时候使用。为了以后能够加载分析规则,就需要正确输入定位xpath。 5.2.3 回复列表的path 回复列表是整理箱中又一层嵌套的容器,不过生成css选择器和截取需要的部分是一样的。此后,为“回复作者”生成path的时候,就要相对于回复列表的path进行截取。 下图可见,经过一系列“开启标注”以后,终于可以选中每一条回复了,对应下图红框的区域,在DOM树上对应多个相同类型的DOM节点。
6. 采集元素节点中的属性和text节点 CSS 选择器只能定位到html元素节点,如果要采集元素中的属性或者元素下面的text节点,需要生成的定位表达式的最右边一段后面增加:
在这之前,爬虫软件已经使用CSS选择器定位到了某个元素,接下来使用上述表达式,以定位到的元素节点为参照,可以进一步定位到其他元素节点、元素的属性节点、元素的文本节点。 比如: <gs_xpath>@href</gs_xpath>:可以用来采集href属性 <gs_xpath>text()[5]</gs_xpath>:可以用来采集元素中的第5个text节点的内容。 |
wangyong: 这是对应的视频教程:<a href="https://www.gooseeker.com/doc/thread-18547-1-1.html" target="_blank">https://www.gooseeker.com/doc/thread-18547-1-1.html</a>