网页跳转基本上可以分成两种情形
- 利用HTTP消息的返回码和新网页地址进行跳转
- 在目标网页HTML中实现跳转。
Web页面信息抓取软件工具包MetaSeeker并不关心哪种跳转方式,都能进行信息抓取。但是,跳转后网页URL实际上已经改变了,在操作MetaStudio时需要注意几点。
网页跳转基本上可以分成两种情形
Web页面信息抓取软件工具包MetaSeeker并不关心哪种跳转方式,都能进行信息抓取。但是,跳转后网页URL实际上已经改变了,在操作MetaStudio时需要注意几点。
假设需要采集京东商城网站上的所有手机产品的信息,包括:商品名、价格、商品图片(MetaSeeker只采集图片网址)等信息。例如,样本网页:http://www.360buy.com/products/652-653-655-0-0-0-0-0-0-0-1-1-1.html。
当前,一些大型社会性媒体(social media)网站(例如,博客、论坛、社交网)大量采用AJAX/Javascript,网页内容动态生成,而且同一个网页上的内容从多个信息源获得,这给网页信息抓取造成了障碍。下面以抓取新浪评论为例讲解怎样使用MetaSeeker抓取Ajax动态内容。现在,很多网站的新闻文章都允许评论,例如,新浪、搜狐、凤凰网等等,下面介绍的方法适用于其它类似网站。
商业舆情监控平台SliceProfile实现了语句级观点分类和倾向性分析。实现观点分类的前提是建立观点词典。
观点词也叫极性词或情感词,英文可以是polar word, sentiment word, opinion word,在英语里面,极性词可以分成两类
MySQL的存储过程(stored procedure)和函数(stored function)统称为stored routines,是否应该采用存储过程在文章Business Logic: To Store or not to Store that is the Question?中进行了详细分析和讨论。存储过程和函数的区别的简要说明参见Stored procedure vs. function。
维基百科对隐马尔可夫模型的定义:
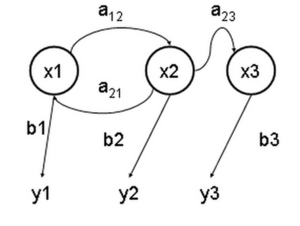
隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数来作进一步的分析,例如模式识别。
近日接连做了多个电子商务网站上的商品信息的提取和数据挖掘解决方案,主要集中在:商品比价、竞争定价分析、销量分析等领域。近期,陆续将这些解决方案整理出来共享给读者,已经发布的解决方案有:
Heuristics,我喜欢的翻译是“探索法” ,而不是“启发式”,因为前者更亲民一些,容易被理解。另外,导致理解困难的一个原因是该词经常出现在一些本来就让人迷糊的专业领域语境中,例如,经常看到某某杀毒软件用启发式方法查毒,普通民众本来就对杀毒软件很敬畏,看到“启发式”就更摸不着北了。
实际上,这个词的解释十分简单,例如,查朗文词典,可以看到:
下面的文字节选自多个文档,收录于此,仅仅作为认识和选择文本分类器的参考,适合程序员和数据挖掘商业应用系统设计者参考,如果想做深入的技术研究,应该查阅下文提及的参考文章。
基于统计的分类算法是主流,主要包括以下几种分类模型:
训练集的选择决定了文本分类器的性能,良好的训练集应该具有下述特征:
如果训练集中存在小类别,所谓的不均衡训练集或数据集,需要一些特殊处理,以确保分类器的性能,例如宏平均和微平均指标
