【注】本文演示怎样用python编程实现k-means聚类。如果想直接使用聚类功能,请使用集搜客数据管家软件,已经集成了聚类功能。使用方法参看《文本聚类分析软件的安装和使用方法》 1 背景介绍 1.1 实验目的 在《Jupyter Notebook使用Python做K-Means聚类分析》和《机器学习库sklearn的K-Means聚类算法的使用方法》这两篇notebook中,我们对kmeans算法做了如下的介绍和实验: 1. 什么是K-means聚类算法? 2. K-means聚类算法应用场景 3. K-means聚类算法步骤 4. 在python下使用随机生成的测试数据进行kmeans算法实验 5. 调用机器学习库sklearn里现成的函数进行kmeans算法实验 有同学留言指出上面的实验都是使用随机生成的测试数据进行的,希望我们基于一些有实际意义的社交媒体数据进行类似的算法实验,这样他们在论文写作时可以更好的参考借鉴。 我们认为这个建议很好,这段时间将使用集搜客GooSeeker网络爬虫工具收集微博或知乎等社交媒体上的原始实验数据,经GooSeeker文本分词和情感分析软件处理后导出各种格式的excel结果表,在sklearn下做各种算法的实验,实验的过程会以JupyterNotebook 形式记录下来与大家分享。 1.2 本notebook实验内容 - 使用GooSeeker文本分词和情感分析软件将文本进行分词处理,导出分词效果数据表,文本已经被切分成一个个词,作为被分析对象
- 利用sklearn的特征工程函数对分词结果进行特征选择,得到数量较少的特征词
- 基于特征词进行聚类分析
- 利用sklearn的降维算法,将被分析数据的维度降到2维,在二维空间展示聚类结果
1.3 实验数据来源 使用知乎_独立话题动态内容采集这个快捷采集,爬取知乎上关于二舅话题的讨论,导出excel格式的采集结果数据。 1.4 实验数据预处理:中文文本分词和选词 将采集得到的知乎二舅话题的excel,导入到Gooseeker文本分词和情感分析软件,经自动分词后,导出“分词效果表”excel。 
图1. 分词结果导出 1.5 sklearn库简介 转载知乎文章《sklearn库主要模块功能简介》的介绍如下: sklearn,全称scikit-learn,是python中的机器学习库,建立在numpy、scipy、matplotlib等数据科学包的基础之上,涵盖了机器学习中的样例数据、数据预处理、模型验证、特征选择、分类、回归、聚类、降维等几乎所有环节,功能十分强大,目前sklearn版本是0.23。与深度学习库存在pytorch、TensorFlow等多种框架可选不同,sklearn是python中传统机器学习的首选库,不存在其他竞争者。 
图2. sklearn-思维导图 1.6 本notebook使用方法 基本操作顺序是: 1. 在GooSeeker分词和文本分析软件上进行任务创建并导入包含原始内容的excel 2. 导出分词效果表 3. 将导出的分词效果表放在本notebook的data/raw文件夹中 4. 从头到尾执行本notebook的单元 注意:每个notebook项目目录都预先规划好了,具体参看《Jupyter Notebook项目目录规划参考》。如果要做多个分析项目,把整个模板目录专门拷贝一份给每个分析项目。 2 第三方库 本notebook使用了sklearn库做k-means算法实验。 如果未安装,请先使用下面的命令安装sklearnm库,再运行实验本notebook: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple sklearn #国内安装使用清华的源,速度快

图3. pip安装 3 准备程序环境 导入必要的Python程序包,设定要分析的文件名变量。在这一系列notebook中,我们都使用以下变量对应GooSeeker分词结果表: - file_word_freq:词频表
- file_seg_effect: 分词效果表
- file_word_choice_matrix: 选词矩阵表
- file_word_choice_match: 选词匹配表
- file_word_choice_result: 选词结果表
- file_co_word_matrix: 共词矩阵表
3.1 导入程序包并声明变量 import pandas as pd import os import numpy as np from sklearn.cluster import KMeans, MiniBatchKMeans from sklearn.decomposition import PCA from sklearn.decomposition import TruncatedSVD from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_extraction.text import HashingVectorizer from sklearn.feature_extraction.text import TfidfTransformer from sklearn.pipeline import make_pipeline from sklearn.preprocessing import Normalizer from sklearn import metrics from time import time %xmode Verbose import warnings warnings.filterwarnings("ignore", category=DeprecationWarning) # 存原始数据的目录 raw_data_dir = os.path.join(os.getcwd(), '..\\..\\data\\raw') # 存处理后的数据的目录 processed_data_dir = os.path.join(os.getcwd(), '..\\..\\data\\processed') filename_temp = pd.Series(['分词效果']) file_seg_effect = ''
输出结果如下: Exception reporting mode: Verbose
3.2 检测data\raw目录下是否有分词效果表 以下的演示以GooSeeker分词和文本分析软件生成的分词效果excel表为例,需要把分词效果表放到本notebook的data/raw文件夹下,如果没有数据表,下面代码执行后将提示“不存在” # 0:'词频', 1:'分词效果', 2:'选词矩阵', 3:'选词匹配', 4:'选词结果', 5:'共词矩阵' print(raw_data_dir + '\r\n') for item_filename in os.listdir(raw_data_dir): if filename_temp[0] in item_filename: file_seg_effect = item_filename continue if file_seg_effect: print("分词效果excel表:", "data\\raw\\", file_seg_effect) else: print("分词效果excel表:不存在")
输出结果如下: C:\Users\work\workspace_219\notebook\知乎话题文本分词后用sklearn做kmeans算法实验\notebook\eda\..\..\data\raw
分词效果excel表: data\raw\ 分词效果-知乎-二舅.xlsx
4 读入分词效果表并观察 4.1 读取分词效果表 df = pd.read_excel(os.path.join(raw_data_dir, file_seg_effect))
输出结果如下: C:\ProgramData\Anaconda3\lib\site-packages\openpyxl\styles\stylesheet.py:214: UserWarning: Workbook contains no default style, apply openpyxl's default warn("Workbook contains no default style, apply openpyxl's default")
4.2 查看前10行数据 使用df.head()函数查看dataframe的前n行数据 df.head(10)
输出结果如下: 
4.3 使用“分词数据”这一列作为实验数据 “分词数据”和“关键词”这2列都是从文本中提取的词汇,通过观察可以看到,“分词数据”就是在词之间插入了空格,显示了分词后的效果;而“关键词”含有的词比较少,是GooSeeker文本分析软件利用自然语言处理算法抽取出来的关键词。 【注意】:本Notebook我们使用“分词数据”这一列作为实验数据,利用sklearn抽取特征词。 df['已分词内容'] = df['分词数据'] df['已分词内容']
输出结果如下: 
Name: 已分词内容, Length: 829, dtype: object 4.4 去掉值为NULL的行 df = df.dropna(axis = 0, how ='any')
4.5 查看有多少篇文档 print("%d 篇文档" % len(df['已分词内容']))
输出结果: 819 篇文档
5 特征选择 原始数据经过分词切分以后,得到的词的数量很大,很多词没有分析价值,除了增加处理的难度,而且会干扰分析结果的合理性,所以,要进行特征选择,可以手工选择,也可以自动选择。本notebook使用sklearn的特征工程函数进行自动特征选择,后面还会发布另一个notebook展示利用GooSeeker分词软件的选词功能进行手工选择,以提高分析结果的合理程度。 本方法使用稀疏向量(Sparse Vectorizer)从训练集中抽取特征,即,从df['已分词内容']字段抽取特征。结束时显示耗时多少及样本数量和特征数量。这个算法使用了一个十分简单的策略:将分词数据转换成一个矩阵,并且统计词频和文档频率,并计算tf-idf,然后由用户决定使用哪些限定条件选择词语。下面我们只限定文档频率:一方面不要文档频率过高的词,那样会引入很多没有意义的噪音词;另一方面不要文档频率过低的词,会造成过拟合而产生分析偏差。下面代码并没有使用tf-idf值。 可以自己实验其他参数,达到更好效果。具体参看TfidfVectorizer的API t0 = time() vectorizer = TfidfVectorizer(max_df=0.7, min_df=0.005, stop_words=None,ngram_range=(1, 2)) X = vectorizer.fit_transform(df['已分词内容'].values.astype('U')) print("完成所耗费时间: %fs" % (time() - t0)) print("样本数量: %d, 特征数量: %d" % X.shape) print('特征抽取完成!')
输出结果如下: 完成所耗费时间: 0.287845s 样本数量: 819, 特征数量: 2271 特征抽取完成!
6 实验一:人工设置K值为3 也就是限定为只分成三类 true_k = 3 #聚类数量
6.1 对文本进行kmeans聚类 labels = df['已分词内容'] km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=5) print("对稀疏数据(Sparse Data) 采用 %s" % km) t0 = time() km.fit(X) print("完成所耗费时间:%0.3fs" % (time() - t0)) print() print("Homogeneity值: %0.3f" % metrics.homogeneity_score(labels, km.labels_)) print("Completeness值: %0.3f" % metrics.completeness_score(labels, km.labels_)) print("V-measure值: %0.3f" % metrics.v_measure_score(labels, km.labels_)) print("Adjusted Rand-Index值: %.3f" % metrics.adjusted_rand_score(labels, km.labels_)) print("Silhouette Coefficient值: %0.3f" % metrics.silhouette_score(X, km.labels_, sample_size=1000)) print() #用训练好的聚类模型反推文档的所属的主题类别 label_prediction = km.predict(X) label_prediction = list(label_prediction)
输出结果如下: 对稀疏数据(Sparse Data) 采用 KMeans(n_clusters=3, n_init=5) 完成所耗费时间:0.210s
Homogeneity值: 0.138 Completeness值: 1.000 V-measure值: 0.242 Adjusted Rand-Index值: 0.000 Silhouette Coefficient值: 0.009
6.2 输出每个簇群去重后的关键词 目的是为了观察每一类中哪些词对聚类打分有贡献,也可以根据词义了解类别代表的意义。 print("每个聚类的TOP关键词:") order_centroids = km.cluster_centers_.argsort()[:, ::-1] # 由于sklearn存在不同版本,这里检测后再调用get_feature_names_out或者get_feature_names if hasattr(vectorizer,'get_feature_names_out'): terms = vectorizer.get_feature_names_out() elif hasattr(vectorizer,'get_feature_names'): terms = vectorizer.get_feature_names() for i in range(true_k): print("簇群 %d " % (i+1), end='') print("该簇群所含文档占比为",'%.4f%%' % (int(label_prediction.count(i))/int(len(df['已分词内容'])))) print("簇群关键词:") wordset = [] for ind in order_centroids[i, :20]: wordset.append(terms[ind].replace(' ','')) for word in wordset: print(' %s ' % word, end='') print('\n------------------------------------------------------------------------------------------------')
输出结果如下: 
6.3 可视化 6.3.1 降维 被分析的数据是高维数据,无法可视化展示出来聚类结果,那么,首先要将高维数据降为成2维或者3维数据。降维必然造成信息损失,到底选择哪个降为算法好,可以多尝试几个,进行对比。 我们使用TruncatedSVD将文档向量从2000维空间降维到2维空间,因为TruncatedSVD恰好适合处理我们当前使用的数据结构。TruncateSVD介绍参看sklearn官网 labels=km.labels_.tolist() #l = km.fit_predict(X) svd = TruncatedSVD(n_components=2).fit(X) datapoint = svd.transform(X)
6.3.2 使用matplotlib进行可视化画图 import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(12, 10)) label1 = [ '#FFFF00', '#008008', '#0000FF','#800080','#FFF5EE','#98FB98','#A0522D', '#FF7F00','#FFC125','#FFFFFF','#FFFAFA','#FFF68F','#FFEFD5','#FFE4E1', '#FFDEAD','#FFC1C1','#FFB90F','#FFA54F','#FF8C00','#C0FF3E','#FF6EB4', '#FF4500','#FF3030','#8A2BE2','#87CEEB','#8470FF','#828282','#7EC0EE', '#7CFC00','#7A8B8B','#79CDCD','#76EE00'] color = [label1[i] for i in labels] plt.scatter(datapoint[:, 0], datapoint[:, 1], c=color) centroids = km.cluster_centers_ centroidpoint = svd.transform(centroids) plt.scatter(centroidpoint[:, 0], centroidpoint[:, 1], marker='^', s=150, c='#000000') plt.show()

图中的黑色三角是每个簇群的中心,不同的颜色代表不同的簇群。分的界限还算清晰。 7 实验二:使用“手肘法”确定最佳的K值 7.1 执行“手肘法” 在《Jupyter Notebook使用Python做K-Means聚类分析》中,我们介绍过“手肘法”确定最佳的K的大小:通过观察明显的拐点来确定最佳的K值。 我们在此也实验下: import matplotlib.pyplot as plt %matplotlib inline plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False n_clusters= 10 wcss = [] for i in range(1,n_clusters): km = KMeans(n_clusters=i, init='k-means++', max_iter=300, n_init=2) km.fit(X) wcss.append(km.inertia_) plt.plot(range(1,n_clusters),wcss) plt.title('肘 部 方 法') plt.xlabel('聚类的数量') plt.ylabel('wcss') plt.show()

手肘法是一个经验方法,而且肉眼观察也因人而异,特别是遇到模棱两可的时候。从上面的图来看,最佳的K值应该是8 # 把人工观察手肘法图的拐点作为K值 true_k = 8 #聚类数量
7.2 对文本进行kmeans聚类 labels = df['已分词内容'] km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=5) print("对稀疏数据(Sparse Data) 采用 %s" % km) t0 = time() km.fit(X) print("完成所耗费时间:%0.3fs" % (time() - t0)) print() print("Homogeneity值: %0.3f" % metrics.homogeneity_score(labels, km.labels_)) print("Completeness值: %0.3f" % metrics.completeness_score(labels, km.labels_)) print("V-measure值: %0.3f" % metrics.v_measure_score(labels, km.labels_)) print("Adjusted Rand-Index值: %.3f" % metrics.adjusted_rand_score(labels, km.labels_)) print("Silhouette Coefficient值: %0.3f" % metrics.silhouette_score(X, km.labels_, sample_size=1000)) print() #用训练好的聚类模型反推文档的所属的主题类别 label_prediction = km.predict(X) label_prediction = list(label_prediction)
输出结果如下: 对稀疏数据(Sparse Data) 采用 KMeans(n_init=5) 完成所耗费时间:0.284s
Homogeneity值: 0.288 Completeness值: 1.000 V-measure值: 0.447 Adjusted Rand-Index值: 0.000 Silhouette Coefficient值: 0.013
7.3 输出每个簇群去重后的关键词 print("每个聚类的TOP关键词:") order_centroids = km.cluster_centers_.argsort()[:, ::-1] # 由于sklearn存在不同版本,这里检测后再调用get_feature_names_out或者get_feature_names if hasattr(vectorizer,'get_feature_names_out'): terms = vectorizer.get_feature_names_out() elif hasattr(vectorizer,'get_feature_names'): terms = vectorizer.get_feature_names() for i in range(true_k): print("簇群 %d " % (i+1), end='') print("该簇群所含文档占比为",'%.4f%%' % (int(label_prediction.count(i))/int(len(df['已分词内容'])))) print("簇群关键词:") wordset = [] for ind in order_centroids[i, :20]: wordset.append(terms[ind].replace(' ','')) for word in wordset: print(' %s ' % word, end='') print('\n------------------------------------------------------------------------------------------------')
输出结果如下: 
7.4 可视化 7.4.1 降维 labels=km.labels_.tolist() #l = km.fit_predict(X) svd = TruncatedSVD(n_components=2).fit(X) datapoint = svd.transform(X)
7.4.2 使用matplotlib进行可视化画图 import matplotlib.pyplot as plt %matplotlib inline plt.figure(figsize=(12, 10)) label1 = [ '#FFFF00', '#008008', '#0000FF','#800080','#FFF5EE','#98FB98','#A0522D', '#FF7F00','#FFC125','#FFFFFF','#FFFAFA','#FFF68F','#FFEFD5','#FFE4E1', '#FFDEAD','#FFC1C1','#FFB90F','#FFA54F','#FF8C00','#C0FF3E','#FF6EB4', '#FF4500','#FF3030','#8A2BE2','#87CEEB','#8470FF','#828282','#7EC0EE', '#7CFC00','#7A8B8B','#79CDCD','#76EE00'] color = [label1[i] for i in labels] plt.scatter(datapoint[:, 0], datapoint[:, 1], c=color) centroids = km.cluster_centers_ centroidpoint = svd.transform(centroids) plt.scatter(centroidpoint[:, 0], centroidpoint[:, 1], marker='^', s=150, c='#000000') plt.show()
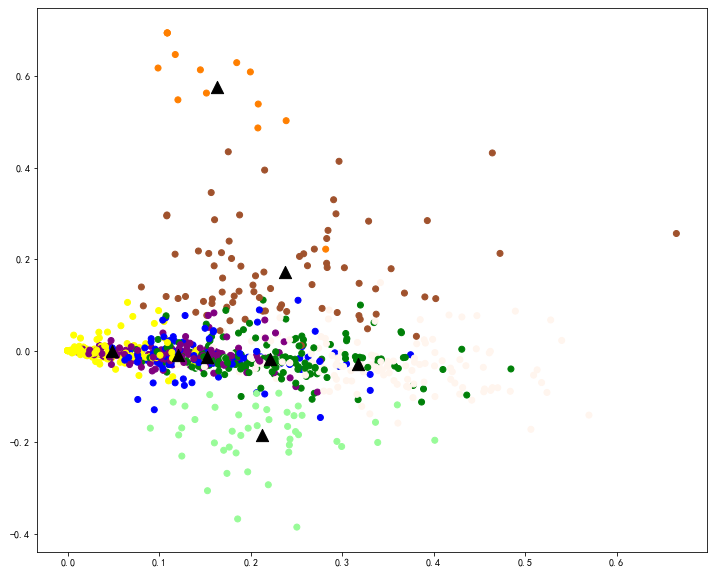
图中的黑色三角是每个簇群的中心,不同的颜色代表不同的簇群。 8 总结 本Notebook使用Gooseeker文本分词和情感分析软件导出的分词效果excel表格,在python下使用sklearn库进行k-means聚类,实验有2个: 实验1. 人工直接设置K值为3进行实验 实验2. 使用“手肘法”人工观察拐点,取K值为7 可视化输出的图看起来可能稍显杂乱,可能是数据样本本身不适合聚类,也可能是聚类算法选择不合适或者参数设置不合适,或者文档向量降维算法选择不合适等等,需要多次实验,改变设置,找到比较好的处理效果。 后续我们会使用来自不同数据源的数据(比如:微博,知乎,新闻等),使用sklearn进行多种算法的实验,在实验中总结和改进。 9 下载源代码 下载notebook源代码请进入:用sklearn的kmeans算法对分词后的社交媒体话题文本做聚类分析 | 




