注:集搜客GooSeeker爬虫从V9.0.2版本开始,爬虫术语“主题”统一改为“任务”,在爬虫浏览器里先命名任务再创建规则,然后登录集搜客官网会员中心的“任务管理”里,就可以查看任务的采集执行情况、管理线索网址以及做调度设置了。 一、操作步骤 集搜客的“飞掠模式”是专门针对那些没有独立网址的弹窗网页,就是指点击之后会弹出一个新页签但网址却不变。而“飞掠模式”可以模拟人的操作,打开一个弹窗采集完之后再打开下一个弹窗继续采集,从而把弹窗网页信息都采集下来。 下面用百度百家为案例,虽然它的弹窗网页是有独立网址的,这种情况最简单的采集方法就是做层级采集,但是为了给大家演示飞掠采集,我们就把它当做是网址不变吧。操作步骤如下:
二、案例规则+操作步骤
第一步:打开网页 1.1,打开GS爬虫浏览器,输入网址等待网页加载完成,再点击“定义规则”,然后输入主题,最后查重一下,主题名不能重复。
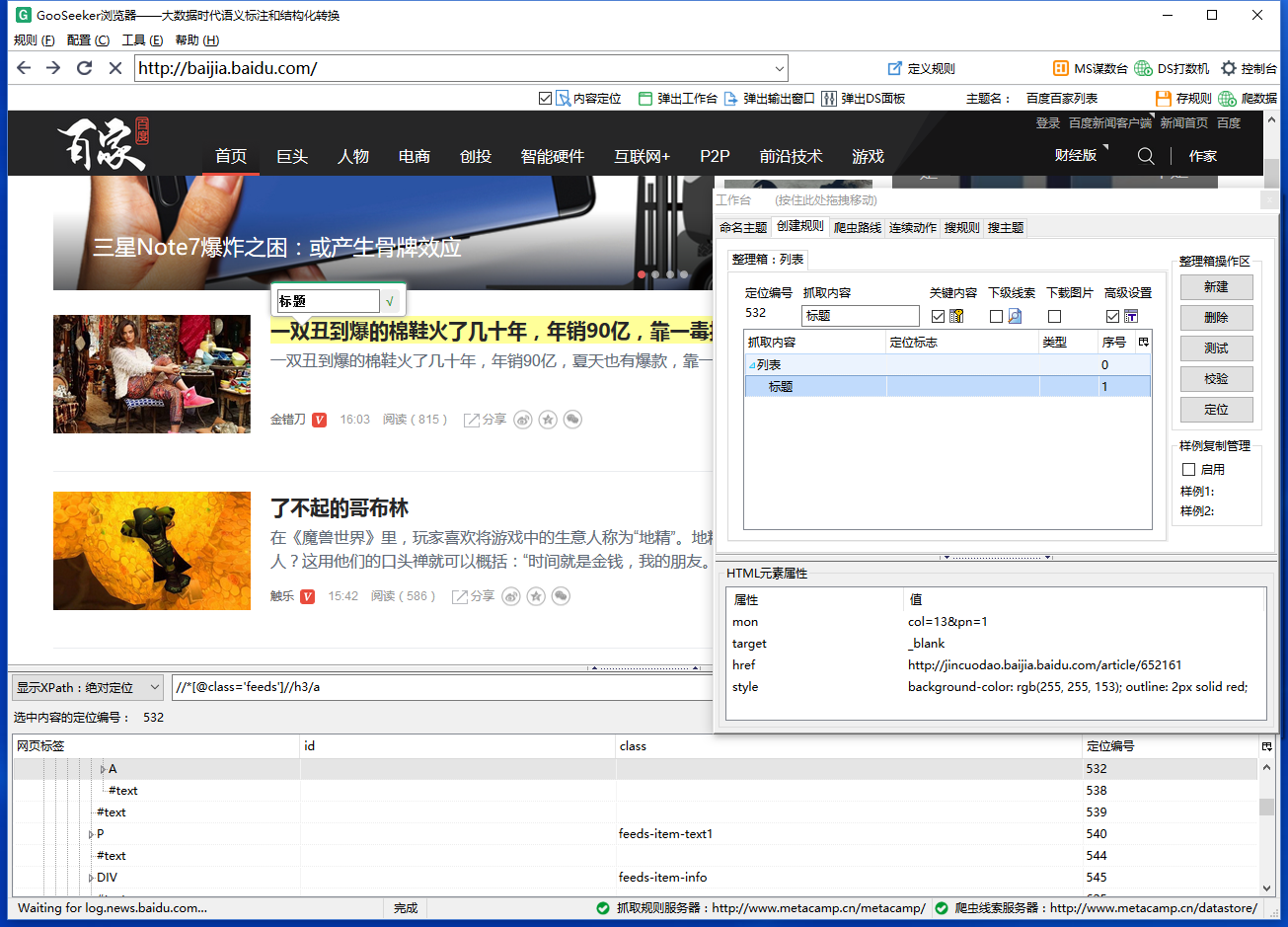
第二步:定义第一级规则 2.1,双击想采的信息,打勾确认。第一级规则可以随意标注一条信息,目的是让爬虫判断是否执行采集。
2.2,本案例是点击每一篇文章标题,然后追踪弹出的网页来采数据,需要写出定位到每个点击对象的xpath表达式。我们可以用“显示xpath”功能来自动定位,找到能够定位到每一个动作对象的xpath。但是对于不太结构化的网页,“显示xpath”就定位不到全部动作对象了,需要自己编写合适的xpath,可以看看xpath教程来掌握。
2.3,在连续动作里新建“点击”动作,填入下级主题名“百度百家文章采集”,勾上“飞掠模式”,填上xpath表达式和动作名称 2.4,点击“存规则”
第三步:定义第二级规则 3.1,再次点击“定义规则”,恢复到普通网页模式,然后点击第一篇文章标题会弹出一个新窗口,在新窗口里定义第二级规则 3.2,双击想采的信息进行标注,做上定位标志映射可以精确采集范围 3.3,点击“测试”,输出结果没有问题就点击“存规则”
第四步:抓数据 4.1,在DS打数机里搜索出第一级规则并运行,点击成功就会弹出一个新窗口采集第二级的网页,采集完弹窗网页就会自动关闭,再点击下一个继续采集。这就是飞掠模式,智能追踪弹窗采数据。 注意:第一级规则的连续动作执行成功后会自动采集下级规则,所以不用单独运行下级规则,特别是下级规则如果没有独立网址,运行时采不到目标数据就会失败。
注意:以上是对案例网站做的采集规则,请根据目标网站的实际情况来定义规则。另外,飞掠模式是旗舰版功能,请先去购买再来做规则采数据。 Tips:没有独立网址的网页,要如何加载和修改规则? 对于没有独立网址的网页,需要先点击到那个页面,然后搜规则,右击选择“仅加载规则”,点击“规则”菜单->“后续分析”完成加载操作,就可以修改规则了。 例如,本案例的第二级规则是没有独立网址,需要先加载出第一级规则,恢复到普通网页模式,点击文章标题,弹出新窗口后,(建议把操作写在第一级规则的备注里,方便查阅),再对第二级规则右击选“仅加载规则”。
若有疑问可以或
 |