每到毕业季,本人的重要工作内容就是提供网络爬虫工具的技术指导,教会做毕业设计的大学生用好数据采集和内容分析软件工具,从而接触和观察到很多有意义的研究课题和研究过程,本文即为一例。 1,研究案例:微博上研究客家文化 最近接触到某高校大学生用内容分析法研究客家文化,样本来自于新浪微博,量化分析微博上关于客家文化的内容呈现,并利用转发和评论数据进行传播分析。 微博因为信息丰富、多样且开放,是最佳的数据渠道,已经产生了大量的微博场域的传统文化数字化生存状态的研究。 2,多种呈现方式的数据采集 GooSeeker每年都要支持各个大学的毕业生采集数据完成他们的毕业设计。GooSeeker有一套微博采集工具,专门面向不希望编写网络爬虫程序的研究者设计的。 例如,可以先从微博关键词搜索入口,把搜到的涉及“客家”的微博内容采集下来,微博的内容呈现方式很丰富,文字、图片、视频都有。这些内容都可以采集下来,分别进行分析。例如,将视频采集下来以后抽取关键帧图片,利用图片分析方法进行分析。 针对重点的微博内容,可以深入采集转发和评论,转发者和评论者,可分析和描述传播的特征和转发者和评论者的传播者特征。还可以根据博主的粉丝数计算传播的量化特征。 GooSeeker推出多个微博采集工具,匹配高校师生从不同角度、不同传播路径、不同内容呈现采集数据的需求。同样也适用于公共领域和民间舆论场分析,市场和商业环境分析等。 3,怎样采集更多数据 网络爬虫软件依据目标网站的开放程度和爬虫授权规则,建立爬虫任务,可以满足科研和商业分析对数据的需求。 在这个客家文化相关内容的研究过程中,研究者发现采集到的数据很少,经过分析发现,微博网站改版了,新版内容呈现方式变了,大量采用瀑布流。鼠标往下滚动才有新内容加载出来,不再有翻页了。如果是翻页方式,网络爬虫会逐页翻页爬取微博内容,而瀑布流方式,网络爬虫需要自动滚鼠标,新加载的内容都显示在当前网页上,网页会变得很长,占用太多内存,终究会受限。 下图展示了进入新版的方法,如果在网络爬虫上已经进入了新版微博,那么GooSeeker微博采集工具箱就会失效。
所以,在网络爬虫的浏览器中,要预先把微博界面设置成老版本,如下图返回老版本
4,文本分词和自然语言处理 内容分析作为一种量化分析手段,首先要把被分析的内容切成某种分析单元。以词作为分析单元是最常见的,因为分词技术很成熟,可以自动化完成。当然,根据研究目的,也许以句子或者段落或者篇章作为分析单元更合适。 GooSeeker针对高校师生做研究的需要,发布了GooSeeker分词和文本挖掘工具。只需把采集到的微博内容以excel格式导入到该工具,就可导出词频词性表。下图罗列了常见的导出表。除此之外,还可以到处文本分类表和情感分类表。
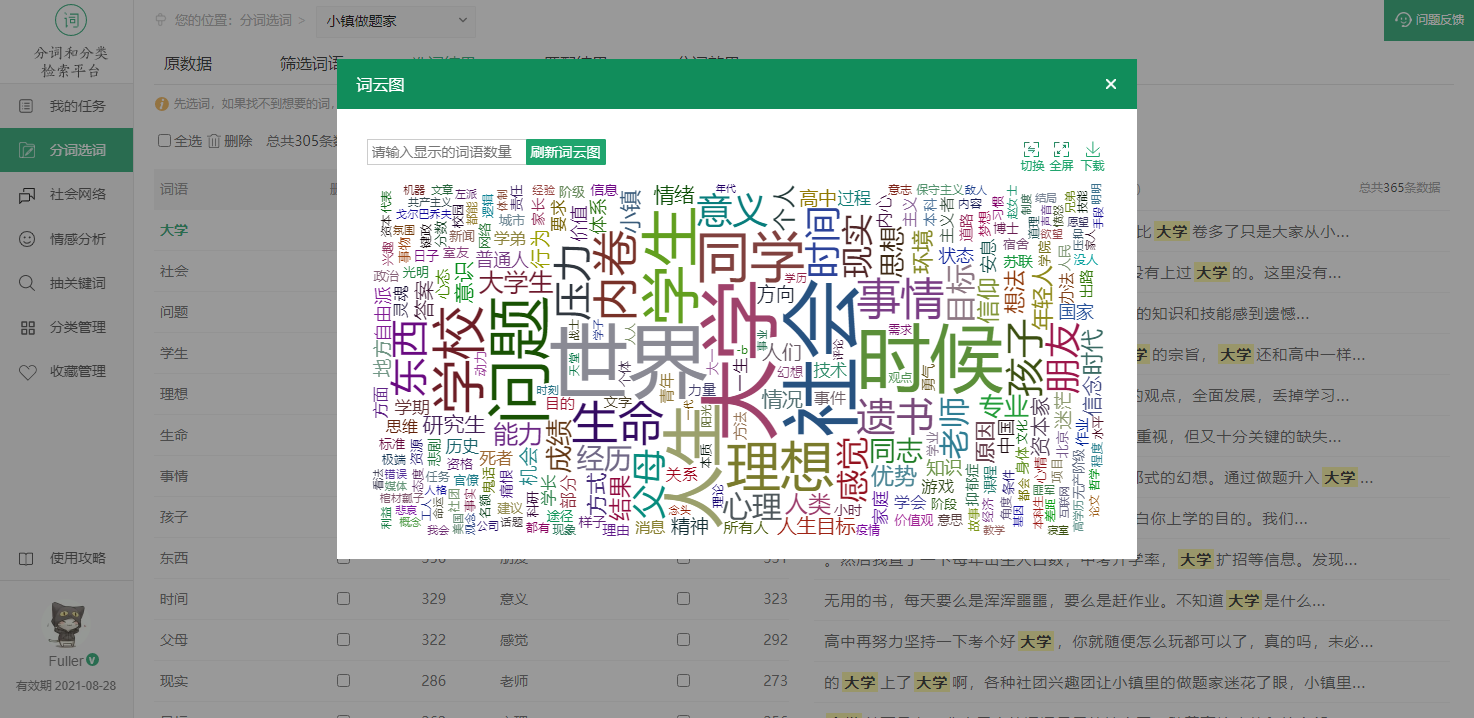
还能生成可视化图,例如,词云图和社交关系图
|