【注意】:本文的目的是演示LDA函数库的基本使用方法,实际编程时要考虑更多工程因素。所以,为了方便大家使用,LDA分析做成了一个有可视化界面的功能模块,不需自己编程,导入数据即可执行LDA分析。该功能放在GooSeeker分词软件的扩展功能模块里面。具体参看《GooSeeker分词扩展模块的安装方法》。 1,背景介绍 1.1 实验目的 在《微博内容分词后怎样用JupyterNotebook做LDA主题模型分析》那篇notebook中,我们以微博上甘肃马拉松事件相关的微博实验了怎样用Python做LDA主题分析。最后观察分析出来的主题似乎不太容易分辨。 本Jupyter Notebook想做一个对比实验,先使用GooSeeker分词和文本分析软件的选词功能,手工选择含义比较明确的词,然后导出选词匹配表。这相当于人工做了降维,对比主题分析的效果,效果肯定是有的,但是怎样手工选词效果最好,还需要实验观察,本文末尾做了一些总结和思考。
1.2 本模板适应的场景 本模板根据GooSeeker分词和文本分析软件生成的选词匹配表,也就是对词语做了人工筛选以后,调用Gensim库做进一步处理。 1.3 使用方法 基本操作顺序是: 1. 在GooSeeker分词和文本分析软件上进行任务创建并导入包含原始内容的excel 2. 执行手工选词,并导出选词匹配表 3. 将导出的选词匹配表放在本notebook的data/raw文件夹中 4. 从头到尾执行本notebook的单元 注意:每个notebook项目目录都预先规划好了,具体参看Jupyter Notebook项目目录规划参考。如果要做多个分析项目,把整个模板目录专门拷贝一份给每个分析项目。 1.4 简要技术说明 更详细的技术说明参看前一篇《微博内容分词后怎样用JupyterNotebook做LDA主题模型分析》,这里只简要补充说明。 本notebook主要实现以下几个步骤: 1. 读取data/raw文件夹中的从分词工具导出的选词匹配表 2. 对选词匹配表进行基本的预处理 3. 使用Gensim库做LDA主题模型实验 2,第三方库 本notebook使用了gensim库和pyLDAvis库,gensim库用于生成BOW词袋和做LDA主题提取, pyLDAvis库用于LDA主题结果的可视化。 请安装下面2个第3方库: pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim #国内安装使用清华的源,速度快 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyLDAvis 3,准备程序环境 导入必要的Python程序包,设定要分析的文件名变量。使用以下变量对应GooSeeker分词结果表: file_word_freq:词频表 file_seg_effect: 分词效果表 file_word_choice_matrix: 选词矩阵表 file_word_choice_match: 选词匹配表 file_word_choice_result: 选词结果表 file_co_word_matrix: 共词矩阵表 【编程细节】本节下面的代码将对上述词频表名变量赋值
4,检测data\raw目录下是否有选词匹配表
5, 读取选词匹配表 以下的演示以GooSeeker分词和文本分析软件生成的选词匹配excel表为例,需要把选词匹配表放到本notebook的data/raw文件夹下
选词匹配表已经把每个句子对应的所有选词放到了“打标词”字段,词与词之间用逗号间隔,所以,只需要执行split,就能分成词数组
6, 对读取到的选词数据(语料库)进行预处理 去除纯数字和只有一个字的词
7,使用Gensim库进行主题模型实验 7.1 根据处理后的语料库生成唯一性词典
7.2 显示词典的前10行
7.3 统计词典中一共有多少个词
7.4 生成矢量列表(list of vectors)
7.5 显示矢量列表的前10行
7.6 使用Gensim库的models.LdaModel方法进行主题建模 注意:本步骤的运行时间长短,和语料库的大小有关。语料库大的话,需要等待的时间会相应比较长 运行完成后会看到提示显示:LDA建模运行结束
7.7 显示提取出的每个主题的相关词
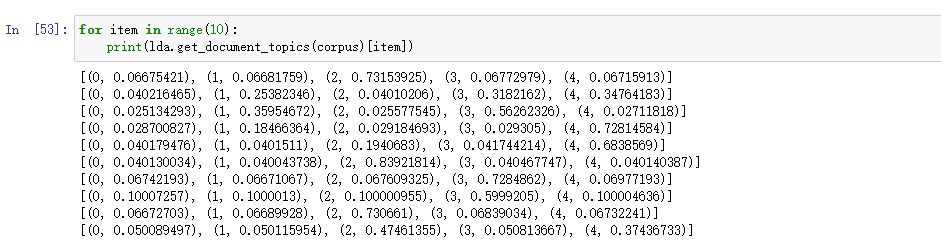
7.8 显示前10篇文档 建模后,会生成每篇文档对应每个主题的概率
8,根据提取的模型数据进行可视化
作为对比,《微博内容分词后怎样用JupyterNotebook做LDA主题模型分析》也计算5个主题,如下图,直观上看选词以后更容易解读。但是,同时也要考虑这些因素: 1. 这两次实验都用了词频,也许改成其他的度量更好一些。比如,tf-idf等等 2. 微博内容很短,观察为文档生成的词向量,绝大多数词频都是1,长文档一定会有不同的效果 3. 仔细看上图和下图某个主题中的词,因为选词刻意避开了一个共有的词,比如“马拉松”,“甘肃”,主题隔离比较开,解读的时候也免受共有词干扰 4. 在pyLDAvis中,通过Slide to adjust relevance,重选lambda,然后再重新运行那个cell,可以看到贡献最大的词的变化 5. 选词以后的测试,变化很小,选词前的测试,变化很大。那么也许可以通过选择合适的lambda作解读。应该有必要去阅读图右下角列出来的参考文献。 6. 作为一个并不擅长编程的人,巧用程序库和程序参数,跟巧妙选词对比,也许是值得斟酌的
9,下载notebook 作为数据探索实验,本notebook放在文件夹:notebook\eda 下载notebook源代码请进入:微博内容分词和选词后建立LDA主题模型 |
syw696666: 最后一步报错 DataFrame.drop() takes from 1 to 2 positional arguments but 3 were given是什么原因呀
wenxin_yoo: 您好,我替换成了自己的数据,也是最后一步显示不出来
wenxin_yoo: 您好,我替换成了自己的数据,也是最后一步显示不出来
17773376573: 请问 可视化最后一步out,为啥出不来任何东西?