上周我们发布了怎样使用Jupyter Notebook计算接近中心度,今天这篇讲解怎样计算中介中心度。 1,背景介绍 这2周我们分享了几篇基于知乎和微博数据做知识传播,主题传播,知识分享和关系路径的学术论文: 该论文将社会网络分析应用于问答社区,辅以内容分析法,将目前国内发展势头最为迅猛的网络问答社区“知乎”作为分析对象,将成员进行知识分享时的互动关系视为社会网络关系,并利用社会网络指标将论坛成员的互动关系量化,探讨成员在知识分享活动中的互动模式,从而探究“知乎”网络问答社区的成员知识分享与传播行为。 2. 基于LDA模型的新冠疫情微博用户主题聚类图谱及主题传播路径研究 该论文基于LDA(latent Dirichlet allocation)模型构建新冠肺炎疫情事件下微博用户的主题聚类图谱,利用困惑度评价指标来确定微博用户的最优主题数和主题分布;利用网络用户转发评论关系构建微博用户主题聚类图谱,提出网络社群间主题传播路径分析方法。 3. 社交网络舆情中意见领袖主题图谱构建及关系路径研究_基于网络谣言话题的分析 该论文是一篇基于大数据驱动的社交网络舆情传播中网络谣言关系路径主题图谱可视化分析的案例,以新浪微博“重庆大巴坠江·非女司机逆行导致”话题为例,使用开源知识图谱工具Neo4j对数据进行主题图谱构建,利用Cypher语言对意见领袖的传播效率、传播路径和关键节点影响力进行分析。 这些论文提到:通过中间中心度、接近中心度,从影响深度上进行社交网络“大V”的传播路径分析或者是知识传播和知识分享。 我们准备针对这几个案例的部分内容,进行探索和实践,今天讲解中介中心度的计算,是试验性质的,后续会基于实际的微博数据和知乎数据进行其它的实验。 1.1,GooSeeker文本分词和情感分析软件已有的社会网络图功能 在之前的多个Notebook中,我们使用了GooSeeker文本分词和情感分析软件,进行中文文本的分词,词频统计,词云图生成,人工筛选,情感分析,社会网络图生成:
截至今天(2021-07-09),除了社交网络图,GooSeeker文本分词和情感分析软件还没有上线其它的网络图或者相关的计算。如果需要进一步的计算,比如,LDA聚类、主题分类、中心度等计算,我们会借助Jupyter Notebook,利用从GooSeeker文本分析软件导出的excel做进一步处理。 1.2,为什么做成Jupyter Notebook模板的形式 GooSeeker每年都要支持各个大学的毕业生采集数据完成他们的毕业设计,提供一系列便于研究者使用的工具。 1. 数据采集工具 GooSeeker有一套微博采集工具,专门面向不希望编写网络爬虫程序的研究者设计的。例如,可以先从微博关键词搜索入口,把搜到的涉及“xx城市空气”的微博话题采集下来,然后把这些话题的微博博文采集下来。微博博文内容呈现方式很丰富,文字、图片、视频都有。这些内容都可以采集下来,分别进行分析。例如,将视频采集下来以后抽取关键帧图片,利用图片分析方法进行分析。 针对重点的微博内容,可以深入采集转发和评论,转发者和评论者,可分析和描述传播的特征和转发者和评论者的传播者特征。还可以根据博主的粉丝数计算传播的量化特征。 GooSeeker推出多个微博采集工具,匹配高校师生从不同角度、不同传播路径、不同内容呈现采集数据的需求。同样也适用于公共领域和民间舆论场分析,市场和商业环境分析等。
2. 自然语言处理工具 数据采集下来之后,需要趁手的工具来做数据处理和数据分析,GooSeeker提供了文本分词和情感分析软件 3. 进一步处理和分析数据:一系列Jupyter Notebook 借助于python的大量第三方库,为数据分析大量强大的工具。 Jupyter Notebook这类交互式数据探索和分析工具代表了一股不容忽视的潮流,借助于Python编程的强大力量,数据加工的能力和灵活性已经有相当明显的优势,尤其是程序代码和文字描述可以混合编排,数据探索和数据描述做完了,一篇研究报告也基本上成型了。 然而Python毕竟是一个全功能的编程语言,对于非编程出身的数据分析师来说,Pandas,Numpy,Matplotlib这些词让人望而生畏。本系列Notebook将设法解决这个问题,让非编程出身的数据分析师能够忽略复杂的编程过程,专注于数据处理和统计分析部分,就像使用Excel的公式一样驾驭Python。 所以,我们将尝试发布一系列Jupyter Notebook,像文档模板,一些基本的程序环境设置、文件操作等固化下来,在设定的分析场景下不需要改动程序代码。而数据处理部分的代码可以根据需要截取选用。每一项功能用一个code cell存代码,不需要的处理功能可以删除。 2,notebook模板的存储结构 本notebook项目目录都预先规划好了,具体参看Jupyter Notebook项目目录规划参考。如果要做多个分析项目,可以把整个模板目录专门拷贝一份给每个分析项目。 3,简要技术说明 在每个功能项单元,如果不需要关心的编程细节,将注明【编程细节】。 本notebook主要实现以下几个步骤: 1. 进行接近中心度计算实验 4,第三方库 decorator库版本5和network配合时有bug,需要安装4.2.2. 安装步骤如下: 1. 以管理员打开Anaconda PowerShell Prompt 2. 执行命令:pip install decorator==4.4.2
5,数据源 无。基于测试数据 6,修改历史 2021-07-12:第一版发布 7,版权说明 本notebook是GooSeeker大数据分析团队开发的,notebook代码可自由共享使用,包括转发、复制、修改、用于其他项目中。 8,准备程序环境 导入必要的Python程序包 import networkx as nx import matplotlib.pyplot as plt import pylab import numpy as np %xmode Verbose import warnings warnings.filterwarnings("ignore", category=DeprecationWarning) 9,实验一:构造含有3个节点的图 为了演示计算过程,构造一个简单的图:3个节点2条边,节点0 -> 节点1 -> 节点2
9.1,自定义网络 #自定义网络 row=np.array([0,1]) col=np.array([1,2]) value=np.array([1,1]) 9.2,生成一个空的有向图 G=nx.DiGraph() 9.3,为这个网络添加节点 for i in range(0,np.size(col)+1): G.add_node(i) 9.4,在网络中添加带权重的边 for i in range(np.size(row)): G.add_weighted_edges_from([(row[i],col[i],value[i])]) 9.5,画网络图 pos=nx.shell_layout(G) nx.draw(G,pos,with_labels=True, node_color='white', edge_color='red', node_size=800, alpha=1 ) pylab.title('BetweennessCentralityTest',fontsize=25) pylab.show() pos=nx.shell_layout(G) nx.draw(G,pos,with_labels=True, node_color='white', edge_color='red', node_size=800, alpha=1 ) pylab.title('BetweennessCentralityTest',fontsize=25) pylab.show()
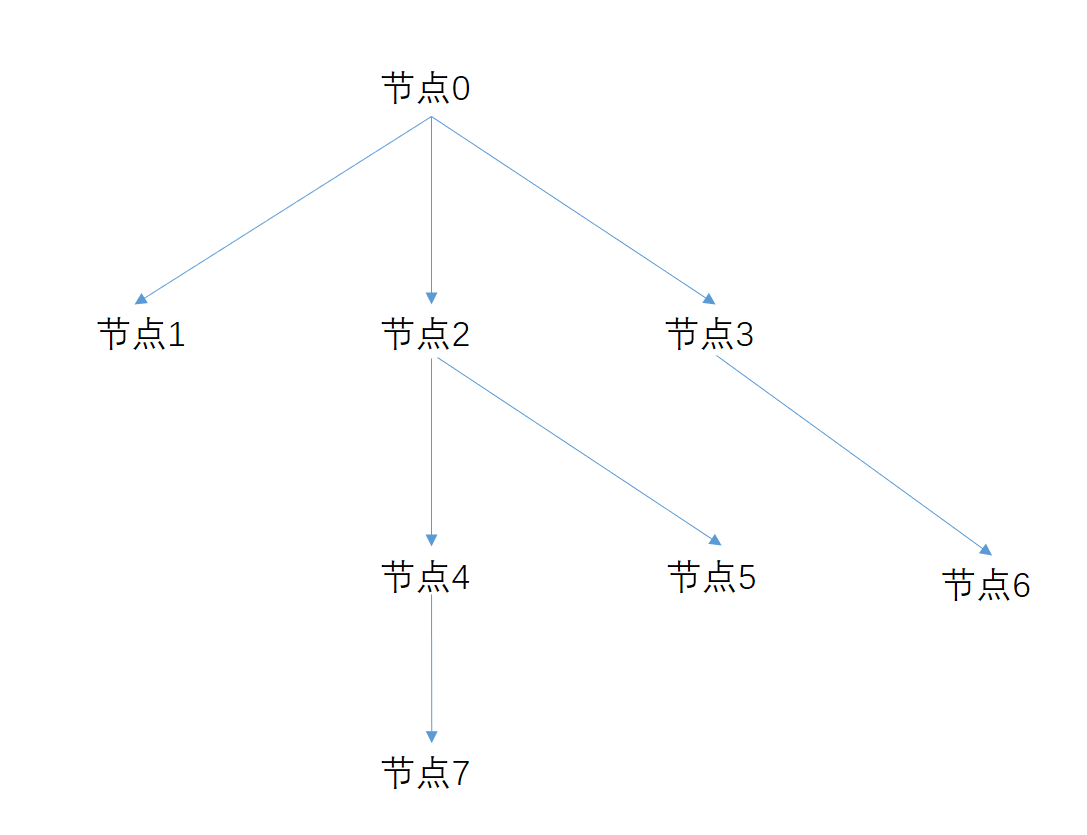
9.6,计算中介中心度并输出值 betweenness = nx.betweenness_centrality(G) #中介中心度 print("输出中介中心度的计算值:") print(betweenness) 输出是: 输出中介中心度的计算值: {0: 0.0, 1: 0.5, 2: 0.0} 9.7,输出结果解读 中介中心性测量的是行动者对资源控制的程度,亦即衡量一个成员是否占据在其他两个成员相互关联的重要捷径上。从此意义上说,该点起到沟通各个他者的桥梁作用。 上图的节点0,2都没有占据沟通其它任意2个节点的位置,所以中介中心度都为0.而节点1处于沟通某2个节点的位置,所以中介中心度的值大于0. 10,实验二:构造一个没有环路的图 如下图,构造一个有8个节点的图做实验
10.1,自定义网络 #自定义网络 row=np.array([0,0,0,3,2,2,4]) col=np.array([1,2,3,6,4,5,7]) value=np.array([1,1,1,1,1,1,1]) 10.2,生成一个空的有向图 G=nx.DiGraph() 10.3,为这个网络添加节点 for i in range(0,np.size(col)+1): G.add_node(i) 10.4,在网络中添加带权重的边 for i in range(np.size(row)): G.add_weighted_edges_from([(row[i],col[i],value[i])]) 10.5,画网络图 pos=nx.shell_layout(G) nx.draw(G,pos,with_labels=True, node_color='white', edge_color='red', node_size=800, alpha=1 ) pylab.title('BetweennessCentralityTest',fontsize=25) pylab.show()
10.6,计算中介中心度并输出值 betweenness = nx.betweenness_centrality(G) #中介中心度 print("输出中介中心度的计算值:") print(betweenness) 输出结果是: 输出中介中心度的计算值: {0: 0.0, 1: 0.0, 2: 0.07142857142857142, 3: 0.023809523809523808, 4: 0.047619047619047616, 5: 0.0, 6: 0.0, 7: 0.0} 10.7,输出结果解读 上图的节点0,1,5,6,7都没有占据沟通其它任意2个节点的位置,所以中介中心度都为0.而节点2,3,4处于沟通某2个节点的位置,所以中介中心度的值大于0. 11,实验三:假设一个主题传播的星状图
11.1,生成一个空的有向图 G=nx.DiGraph() 11.2,为这个网络添加节点和边 G.add_edge('userA', 'user11') #添加边 G.add_edge('userA', 'user12') #添加边 G.add_edge('userA', 'user13') #添加边 G.add_edge('userA', 'user14') #添加边 G.add_edge('userA', 'user15') #添加边 G.add_edge('userA', 'user16') #添加边 11.3,画网络图 pos=nx.shell_layout(G) nx.draw(G,pos,with_labels=True, node_color='white', edge_color='red', node_size=800, alpha=1 ) pylab.title('BetweennessCentralityTest',fontsize=25) pylab.show()
11.4,计算中介中心度并输出值 betweenness = nx.betweenness_centrality(G) #中介中心度 print("输出中介中心度的计算值:") print(betweenness) 输出结果是: 输出中介中心度的计算值: {'userA': 0.0, 'user11': 0.0, 'user12': 0.0, 'user13': 0.0, 'user14': 0.0, 'user15': 0.0, 'user16': 0.0} 11.5,输出结果解读 上图的所有节点都没有占据沟通其它任意2个节点的位置,所以中介中心度都为0. 12,后续的实验 1. 基于知乎主题传播的实验 2. 基于微博转发,评论,点赞的传播路径实验 |