1 介绍 上一篇Jupyter notebook《用MST(minimum or maximum spanning tree)算法简化共词关系图》我们讲解了怎样用networkx的MST算法简化由GooSeeker分词和情感分析软件共词矩阵生成的社会网络图。 社会网络分析法作为一个专业理论体系建立起来已经超过半个世纪了,MST只是其中一个最基础的算法,在networkx程序包中还有很多算法。上一篇我们用MST的时候,发现裁剪的太厉害,而且由于两个普遍词造成MST树几乎就是一个星状结构,很难观察到有价值的信息。当时我们计划采用其他度量距离的方法再看看能否有更多发现。而在这之前,我们先试试通过设定边的权重阈值,将权重低于阈值的边裁剪掉。 用共词矩阵生成的社会网络图上,边的权重就是两个词共同出现的次数,我们只保留少量的边,看看是否能提升分析效果。 2 使用方法 为执行本notebook的分析任务,操作顺序是: - 在GooSeeker分词和文本分析软件上创建文本分析任务并导入包含待分析内容的excel,分析完成后导出共词矩阵表
- 将导出的excel表放在本notebook的data/raw文件夹中
- 从头到尾执行本notebook的单元
注意:GooSeeker发布的每个notebook项目目录都预先规划好了,具体参看Jupyter Notebook项目目录规划参考。如果要新做一个分析项目,把整个模板目录拷贝一份给新项目,然后编写notebook目录下的ipynb文件。 3 修改历史 2022-08-18:第一版发布 4 版权说明 本notebook是GooSeeker大数据分析团队开发的,所分析的源数据是GooSeeker分词和文本分析软件生成的,本notebook中的代码可自由共享使用,包括转发、复制、修改、用于其他项目中。 5 准备运行环境 5.1 引入需要用到的库 # -*- coding: utf-8 -*- import os import numpy as np import pandas as pd import networkx as nx import matplotlib.pyplot as plt import pylab %xmode Verbose import warnings # 软件包之间配套时可能会使用过时的接口,把这类告警忽略掉可以让输出信息简练一些 warnings.filterwarnings("ignore", category=DeprecationWarning) # 把RuntimeWarning忽略掉,不然画图的时候有太多告警了 warnings.filterwarnings("ignore", category=RuntimeWarning)
5.2 设置中文字体 因为含有中文,plt画图会显示下面的错误信息: C:\ProgramData\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:238: RuntimeWarning: Glyph 32993 missing from current font. font.set_text(s, 0.0, flags=flags)
为了防止plt显示找不到字体的问题,先做如下设置。参看glyph-23130-missing-from-current-font #plt.rcParams['font.sans-serif']=['SimHei'] # 上面一行在macOS上没有效果,所以,使用下面的字体 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False
5.3 常量和配置 在我们发布的一系列Jupyter Notebook中,凡是处理GooSeeker分词软件导出的结果文件的,都给各种导出文件起了固定的名字。为了方便大家使用,只要把导出文件放在data/raw文件夹,notebook就会找到导出文件,赋值给对应的文件名变量。下面罗列了可能用到的文件名变量: - file_all_word:词频表
- file_chosen_word: 选词结果表
- file_seg_effect: 分词效果表
- file_word_occurrence_matrix: 选词矩阵表(是否出现)
- file_word_frequency_matrix: 文档词频对应矩阵
- file_word_document_match: 选词匹配表
- file_co_word_matrix: 共词矩阵表
pd.set_option('display.width', 1000) # 设置字符显示宽度 pd.set_option('display.max_rows', None) # 设置显示最大
# np.set_printoptions(threshold=np.inf) # threshold 指定超过多少使用省略号,np.inf代表无限大 # 存原始数据的目录 raw_data_dir = os.path.join(os.getcwd(), '../../data/raw') # 存处理后的数据的目录 processed_data_dir = os.path.join(os.getcwd(), '../../data/processed') filename_temp = pd.Series(['词频','分词效果','选词矩阵','选词匹配','选词结果','共词矩阵']) file_all_word = '' file_seg_effect = '' file_word_occurrence_matrix = '' file_word_frequency_matrix = '' file_word_document_match = '' file_chosen_word = '' file_co_word_matrix = ''
5.4 检测data\raw目录下是否有GooSeeker分词结果表 在本notebook只使用共词矩阵表,下面的代码将检查data/raw中有没有这个表,如果没有会报错,后面的程序就没法执行了。 # 0:'词频', 1:'分词效果', 2:'选词矩阵', 3:'选词匹配', 4:'选词结果', 5:'共词矩阵' print(raw_data_dir + '\r\n') for item_filename in os.listdir(raw_data_dir): if filename_temp[5] in item_filename: file_co_word_matrix = item_filename continue if file_co_word_matrix: print("共词矩阵表:", "data/raw/", file_co_word_matrix) else: print("共词矩阵表:不存在")
输出结果像这样: C:\Users\work\workspace_219\notebook\发布-二舅\设置边权重阈值裁剪共词关系社会网络图\notebook\eda\../../data/raw 共词矩阵表: data/raw/ 共词矩阵-知乎-二舅.xlsx
6 读取共词矩阵表并存入矩阵 读入过程不展开讲解,具体参看《共词分析中的共词关系是怎么得到的?》 6.1 用pandas dataframe读入共词矩阵 df_co_word_matrix = pd.read_excel(os.path.join(raw_data_dir, file_co_word_matrix)) df_co_word_matrix.head(2)

6.2 提取字段名 将用于给graph的node命名 coword_names = df_co_word_matrix.columns.values[1:] print("There are ", len(coword_names), " words") coword_names
输出结果: There are 133 words array(['世界', '二舅', '现实', '时候', '故事', '人生', '事情', '苦难', '精神', '底层', '内耗', '时代', '人民', '视频', '社会', '人们', '问题', '母亲', '普通人', '国家', '农村', '作者', '东西', '中国', '回村', '作品', '时间', '残疾', '原因', '孩子', '命运', '个人', '力量', '年轻人', '价值', '意义', '一生', '经历', '感觉', '方式', '大学', '房子', '年代', '条件', '观众', '地方', '评论', '媒体', '城市', '态度', '村里', '能力', '本质', '青年', '文化', '能量', '医生', '老师', '办法', '大众', '电影', '鸡汤', '机会', '压力', '父母', '穷人', '小镇', '角度', '悲剧', '收入', '关系', '内容', '视角', '老人', '内心', '环境', '流量', '情况', '情绪', '文案', '目的', '观点', '人类', '农民', '资本', '个体', '励志', '代表', '平台', '文艺创作', '分钟', '经济', '想法', '朋友', '心理', '群众', '人物', '日子', '资源', '思想', '历史', '残疾人', '文艺', '编剧', '木匠', '过程', '生命', '身体', '状态', '艺术', '政府', '物质', '人人', '医疗', '村子', '文学', '热度', '心态', '网友', '周劼', '机制', '宁宁', '外甥', '兴趣', '主流', '公子', '父亲', '官方', '文艺作品', '好人', '源泉', '公寓', '彭叔'], dtype=object)
6.3 生成矩阵数据结构 # 使用astype函数对数据类型进行转换,否则,下面画图的时候可能会报错 array_co_word_matrix = df_co_word_matrix.values[:, 1:].astype(float) array_co_word_matrix
输出结果: array([[101., 74., 24., ..., 1., 1., 1.], [ 74., 403., 59., ..., 5., 1., 1.], [ 24., 59., 76., ..., 1., 1., 1.], ..., [ 1., 5., 1., ..., 7., 0., 0.], [ 1., 1., 1., ..., 0., 1., 0.], [ 1., 1., 1., ..., 0., 0., 1.]])
统计一下词数 word_num = len(array_co_word_matrix) word_num
输出结果:133 6.4 修改矩阵对角线的值 在共词矩阵中,除了对角线上的值以外,其他地方的值表示两个词同时出现的文档数量,而对角线的值是某个词自己出现的文档数量。仔细观察前面的notebook中画的图,每个节点上都有一个自环边,表示这个词出现的文档数量。 【注意】在不同的平台上,可能是pyplot的缺省设置不一样,有时候会看到没有自环边。 本notebook将根据边权重的阈值删减边,有些节点就会变成孤立的点,如果还有自环边,那么就没法当成孤立的点进行剔除,所以,我们预先在矩阵中将对角线的值设置成0 np.fill_diagonal(array_co_word_matrix, 0) array_co_word_matrix
输出结果: array([[ 0., 74., 24., ..., 1., 1., 1.], [74., 0., 59., ..., 5., 1., 1.], [24., 59., 0., ..., 1., 1., 1.], ..., [ 1., 5., 1., ..., 0., 0., 0.], [ 1., 1., 1., ..., 0., 0., 0.], [ 1., 1., 1., ..., 0., 0., 0.]])
7 生成图并进行探索 7.1 从NumPy数组生成networkx图 参看networkx文档,有专门的函数从其他数据结构直接生成graph graph_co_word_matrix = nx.from_numpy_array(array_co_word_matrix) print(nx.info(graph_co_word_matrix)) #graph_co_word_matrix.edges(data=True)
输出结果: Name: Type: Graph Number of nodes: 133 Number of edges: 7710 Average degree: 115.9398
7.2 给node加上label 如果不加label,画出来的图上的每个节点只是一个编号,加上label可以看到节点对应的词。根据How-do-I-label-a-node-using-networkx-in-python,重新命名labels for idx, node in enumerate(graph_co_word_matrix.nodes()): print("idx=", idx, "; node=", node) coword_labels[node] = coword_names[idx] graph_co_word_matrix = nx.relabel_nodes(graph_co_word_matrix, coword_labels) sorted(graph_co_word_matrix)

for idx, node in enumerate(graph_co_word_matrix.nodes()): print("idx=", idx, "; node=", node)

7.3 画图 figure函数的使用方法参看pyplot官网 。其他参考资料:
# 方案1:用pylab画图 #pos=nx.shell_layout(graph_co_word_matrix) #nx.draw(graph_co_word_matrix,pos,with_labels=True, node_color='white', edge_color='grey', node_size=1200, alpha=1 ) #pylab.title('co-word matrix',fontsize=25) #pylab.show() # 方案2 #pos = nx.circular_layout(maximum_tree) pos = nx.spring_layout(graph_co_word_matrix) plt.figure(1,figsize=(20,20)) nx.draw(graph_co_word_matrix, pos, node_size=10, with_labels=True, font_size=22, font_color="red") #nx.draw(graph_co_word_matrix, pos, with_labels=True) #nx.draw_networkx_labels(graph_co_word_matrix, pos, labels) plt.show()

8 设定阈值删减边 8.1 选择阈值 删掉多少边比较好呢?我们先看看这些位置上的边权重是多少: coword_median = np.median(array_co_word_matrix) coword_median
输出结果:3.0 coword_max = np.max(array_co_word_matrix) coword_max
输出结果:204.0 coword_min = np.min(array_co_word_matrix) coword_min
输出结果:0.0 coword_per10 = np.percentile(array_co_word_matrix, 90) coword_per10
输出结果:11.0 coword_per2 = np.percentile(array_co_word_matrix, 98) coword_per2
输出结果:25.0 8.2 删掉权重小于中位数的边 根据RuntimeError filtering the edges with weight below the threshold - Networkx,可以拷贝一个新图,在上面删除权重低的边。 graph_coword_median = graph_co_word_matrix.copy() graph_coword_median.remove_edges_from([(n1, n2) for n1, n2, w in graph_coword_median.edges(data="weight") if w < coword_median]) pos = nx.spring_layout(graph_coword_median) plt.figure(1,figsize=(30,30)) nx.draw(graph_coword_median, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

8.3 删除基于中位数裁剪的图的孤立点 graph_coword_median.remove_nodes_from(list(nx.isolates(graph_coword_median))) #pos = nx.circular_layout(graph_coword_median) pos = nx.spring_layout(graph_coword_median) plt.figure(1,figsize=(20,20)) nx.draw(graph_coword_median, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

8.4 删掉权重小于10%分位的边 graph_coword_per10 = graph_co_word_matrix.copy() graph_coword_per10.remove_edges_from([(n1, n2) for n1, n2, w in graph_coword_per10.edges(data="weight") if w < coword_per10]) pos = nx.spring_layout(graph_coword_per10) plt.figure(1,figsize=(30,30)) nx.draw(graph_coword_per10, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

8.5 删除基于10%分位裁剪的图的孤立点 graph_coword_per10.remove_nodes_from(list(nx.isolates(graph_coword_per10))) #pos = nx.circular_layout(graph_coword_per10) pos = nx.spring_layout(graph_coword_per10) plt.figure(1,figsize=(20,20)) nx.draw(graph_coword_per10, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

8.6 删除权重小于2%分位的边 graph_coword_per2 = graph_co_word_matrix.copy() graph_coword_per2.remove_edges_from([(n1, n2) for n1, n2, w in graph_coword_per2.edges(data="weight") if w < coword_per2]) pos = nx.spring_layout(graph_coword_per2) plt.figure(1,figsize=(30,30)) nx.draw(graph_coword_per2, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

8.7 删除基于2%分位裁剪的图的孤立点 graph_coword_per2.remove_nodes_from(list(nx.isolates(graph_coword_per2))) #pos = nx.circular_layout(graph_coword_per2) pos = nx.spring_layout(graph_coword_per2) plt.figure(1,figsize=(20,20)) nx.draw(graph_coword_per2, pos, node_size=10, with_labels=True, font_size=22, font_color="blue") plt.show()

9 点度中心性分析 经过裁剪边以后,糊成一片的图越来越显出星状结构,但是依然保留着权重很大的环状子图,不像MST只剩下没有环的树。 9.1 定义一个公共画图函数 下面的代码来自NetworkX的中心性分析案例:plot_degree.html。将用来从多个角度观察点度中心性。 def diplay_graph_degree(G): seq_degree = sorted((d for n, d in G.degree()), reverse=True) dmax = max(seq_degree) fig = plt.figure("Degree of the count graph", figsize=(8, 8)) # Create a gridspec for adding subplots of different sizes axgrid = fig.add_gridspec(5, 4) ax0 = fig.add_subplot(axgrid[0:3, :]) Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0]) pos = nx.spring_layout(Gcc, seed=10396953) nx.draw_networkx_nodes(Gcc, pos, ax=ax0, node_size=20) nx.draw_networkx_edges(Gcc, pos, ax=ax0, alpha=0.4) ax0.set_title("Connected components of G") ax0.set_axis_off() ax1 = fig.add_subplot(axgrid[3:, :2]) ax1.plot(seq_degree, "b-", marker="o") ax1.set_title("Degree Rank Plot") ax1.set_ylabel("Degree") ax1.set_xlabel("Rank") ax2 = fig.add_subplot(axgrid[3:, 2:]) ax2.bar(*np.unique(seq_degree, return_counts=True)) ax2.set_title("Degree histogram") ax2.set_xlabel("Degree") ax2.set_ylabel("# of Nodes") fig.tight_layout() plt.show()
9.2 针对按中位数裁剪的图的处理 9.2.1 对点度中心性排序 sorted(graph_coword_median.degree(), key=lambda x: x[1], reverse=True)

9.2.2 综合展示点度中心性 diplay_graph_degree(graph_coword_median)

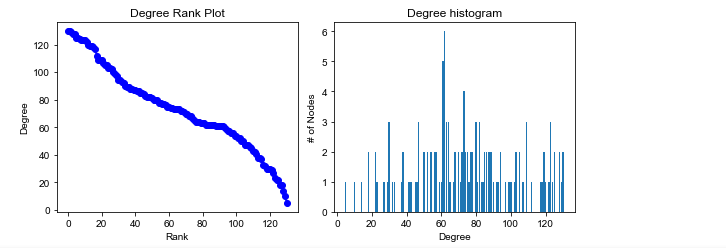
9.3 针对按10%分位数裁剪的图的处理 9.3.1 对点度中心性排序 sorted(graph_coword_per10.degree(), key=lambda x: x[1], reverse=True)

9.3.2 综合展示点度中心性 diplay_graph_degree(graph_coword_per10)

9.4 针对按2%分位数裁剪的图的处理 9.4.1 对点度中心性排序 sorted(graph_coword_per2.degree(), key=lambda x: x[1], reverse=True)

9.4.2 综合展示点度中心性 diplay_graph_degree(graph_coword_per2)

10 总结 《用MST(minimum or maximum spanning tree)算法简化共词关系图》说的普遍词造成的影响问题其实没有改善,稀有词却可以很有效地剔除掉,所以,是另外一种有效的观察词的聚集情况的视图。 后面的notebook我们将开始探索采用协方差和皮尔森相关系数度量词与词之间的关系,看看有什么发现。 11 下载Jupyter Notebook源代码 下载notebook源代码请进入:根据边权重阈值裁剪共词关系社会网络图 | 




