1 介绍 在《共词分析中的共词关系是怎么得到的?》一篇我们讲解了共词关系描述了什么,同时也提到,如果为了衡量词与词之间在文档中的分布规律是否相似,还有其他一些度量方法。前面,通过《用networkx和python编程可视化分析共词关系图》这篇notebook,我们学会了怎样用社会网络图分析和观察共词关系,通过《用MST(minimum or maximum spanning tree)算法简化共词关系图》和《设置边权重阈值裁剪共词关系图》学会了两种简化图的方法,这两种方法提供了两个不同的视图去观察共词关系。 这些分析同样的可以用在co-word之外的co-auther, co-cited, co-reference等等社会网络分析中。用co-word进行演练有个好处:借助于GooSeeker分词和情感分析软件,一系列数据集随手拈来,而且可以很有意思地紧跟热点,想研究二舅就研究二舅,想研究糖水爷爷就研究糖水爷爷。 本notebook准备使用协方差矩阵来描述共词关系,同共词矩阵相比,这可以看作是更加细腻的考察,因为通过去中心化计算,词在文档中的分布规律不再是非负数描述的,而是有正有负,可以看作是有涨有跌,这样,如果两个词有相同的涨跌,那么他们的协方差就会比较大,同时跌虽然都是负值,两个负数相乘变成正数,为协方差的最终结果给予正向的贡献。 看起来求协方差是挺美好的,但是,同时可以观察到一些低文档频率的词带来的冲击,这在前面的notebook中已经做了一些简单的解读。顺着这些问题可以一直实验下去,比如,已经计算了协方差矩阵,是否可以再进一步计算特征空间,进行PCA运算,进行降维计算,对所选词进行删减;或者演练一下LDA(Linear Discriminant Analysis)并对比辨析一下Latent Dirichlet Allocation,再走到word2vec等等,把algebraic models走一圈然后延伸到多层神经网络。虽然很多计算场景是否有用都有一些基本定论,学习演练一下也未尝不可,也可能会有一些新发现。 好吧,转了一圈还是要落实到脚下,迈这一步的目的是想尝试一下经过协方差计算以后,再利用networkx的图计算算法,看看在共词关系上能有什么新发现。 2 使用方法 为执行本notebook所述的分析任务,操作顺序是: - 在GooSeeker分词和文本分析软件上创建文本分析任务并导入包含待分析内容的excel,分析完成后导出选词矩阵表
- 将导出的excel表放在本notebook的data/raw文件夹中
- 从头到尾执行本notebook的单元
注意:GooSeeker发布的每个notebook项目目录都预先规划好了,具体参看Jupyter Notebook项目目录规划参考。如果要新做一个分析项目,把整个模板目录拷贝一份给新项目,然后编写notebook目录下的ipynb文件。 3 修改历史 2022-08-20:第一版发布 4 版权说明 本notebook是GooSeeker大数据分析团队开发的,所分析的源数据是GooSeeker分词和文本分析软件生成的,本notebook中的代码可自由共享使用,包括转发、复制、修改、用于其他项目中。 5 准备运行环境 5.1 引入需要用到的库 # -*- coding: utf-8 -*- import os import numpy as np import pandas as pd import networkx as nx import matplotlib.pyplot as plt import pylab %xmode Verbose import warnings # 软件包之间配套时可能会使用过时的接口,把这类告警忽略掉可以让输出信息简练一些 warnings.filterwarnings("ignore", category=DeprecationWarning) # 把RuntimeWarning忽略掉,不然画图的时候有太多告警了 warnings.filterwarnings("ignore", category=RuntimeWarning)
5.2 设置中文字体 因为含有中文,plt画图会显示下面的错误信息: C:\ProgramData\Anaconda3\lib\site-packages\matplotlib\backends\backend_agg.py:238: RuntimeWarning: Glyph 32993 missing from current font. font.set_text(s, 0.0, flags=flags)
为了防止plt显示找不到字体的问题,先做如下设置。参看glyph-23130-missing-from-current-font #plt.rcParams['font.sans-serif']=['SimHei'] # 上面一行在macOS上没有效果,所以,使用下面的字体 plt.rcParams['font.sans-serif'] = ['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False
5.3 常量和配置 在我们发布的一系列Jupyter Notebook中,凡是处理GooSeeker分词软件导出的结果文件的,都给各种导出文件起了固定的名字。为了方便大家使用,只要把导出文件放在data/raw文件夹,notebook就会找到导出文件,赋值给对应的文件名变量。下面罗列了可能用到的文件名变量: - file_all_word:词频表
- file_chosen_word: 选词结果表
- file_seg_effect: 分词效果表
- file_word_occurrence_matrix: 选词矩阵表(是否出现)
- file_word_frequency_matrix: 文档词频对应矩阵
- file_word_document_match: 选词匹配表
- file_co_word_matrix: 共词矩阵表
pd.set_option('display.width', 1000) # 设置字符显示宽度 pd.set_option('display.max_rows', None) # 设置显示最大 # np.set_printoptions(threshold=np.inf) # threshold 指定超过多少使用省略号,np.inf代表无限大 # 存原始数据的目录 raw_data_dir = os.path.join(os.getcwd(), '../../data/raw') # 存处理后的数据的目录 processed_data_dir = os.path.join(os.getcwd(), '../../data/processed') filename_temp = pd.Series(['词频','分词效果','选词矩阵','选词匹配','选词结果','共词矩阵']) file_all_word = '' file_seg_effect = '' file_word_occurrence_matrix = '' file_word_frequency_matrix = '' file_word_document_match = '' file_chosen_word = '' file_co_word_matrix = ''
5.4 检测data\raw目录下是否有GooSeeker分词结果表 在本notebook使用选词矩阵表,不再是共词矩阵表,因为选词矩阵表含有更丰富的内容:每个词在每篇文档中出现的次数。下面的代码将检查data/raw中有没有这个表,如果没有会报错,后面的程序就没法执行了。 # 0:'词频', 1:'分词效果', 2:'选词矩阵', 3:'选词匹配', 4:'选词结果', 5:'共词矩阵' print(raw_data_dir + '\r\n') for item_filename in os.listdir(raw_data_dir): if filename_temp[2] in item_filename: file_word_frequency_matrix = item_filename continue if file_word_frequency_matrix: print("选词矩阵表:", "data/raw/", file_word_frequency_matrix) else: print("选词矩阵表:不存在")
输出结果像这样: C:\Users\work\workspace\notebook\发布-二舅\对共词关系求协方差矩阵后是否有更好的社会网络分析结果?\notebook\eda\../../data/raw 选词矩阵表: data/raw/ 选词矩阵-知乎-二舅.xlsx
6 读取选词矩阵表并存入矩阵 读入过程不展开讲解,具体参看《共词分析中的共词关系是怎么得到的?》 6.1 用pandas dataframe读入选词矩阵 df_word_frequency_matrix = pd.read_excel(os.path.join(raw_data_dir, file_word_frequency_matrix)) df_word_frequency_matrix.head(2)

6.2 提取字段名 将用于给graph的node命名 coword_names = df_word_frequency_matrix.columns.values[2:] print("There are ", len(coword_names), " words") coword_names
输出结果如下: There are 133 words array(['二舅', '视频', '苦难', '精神', '内耗', '故事', '问题', '社会', '时代', '人生', '时候', '世界', '作者', '残疾', '中国', '作品', '农村', '城市', '现实', '电影', '命运', '兴趣', '人民', '东西', '底层', '媒体', '文化', '年轻人', '人们', '事情', '感觉', '观众', '普通人', '孩子', '收入', '一生', '经历', '彭叔', '内容', '编剧', '鸡汤', '价值', '年代', '时间', '原因', '网友', '能力', '老人', '评论', '能量', '励志', '村里', '文案', '资本', '医生', '文艺创作', '艺术', '流量', '国家', '内心', '个人', '情绪', '大众', '朋友', '农民', '意义', '母亲', '悲剧', '好人', '大学', '观点', '机会', '残疾人', '思想', '文艺', '机制', '压力', '力量', '公寓', '角度', '父母', '分钟', '心理', '外甥', '小镇', '方式', '政府', '环境', '人物', '老师', '物质', '态度', '父亲', '条件', '个体', '关系', '群众', '历史', '情况', '穷人', '房子', '人人', '本质', '回村', '木匠', '状态', '官方', '主流', '平台', '心态', '想法', '周劼', '办法', '视角', '生命', '青年', '热度', '公子', '文学', '经济', '人类', '源泉', '资源', '代表', '地方', '宁宁', '文艺作品', '医疗', '目的', '日子', '身体', '村子', '过程'], dtype=object)
6.3 生成矩阵数据结构 # 使用astype函数对数据类型进行转换,否则,下面画图的时候可能会报错 array_word_frequence_matrix = df_word_frequency_matrix.values[:, 2:].astype(float) array_word_frequence_matrix
输出结果如下: array([[0., 1., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], [0., 0., 0., ..., 0., 0., 0.], ..., [0., 0., 0., ..., 0., 0., 0.], [1., 0., 0., ..., 0., 0., 0.], [1., 0., 0., ..., 0., 0., 0.]])
7 求协方差矩阵 在《共词分析中的共词关系是怎么得到的?》我们说过,如果选词矩阵称为R,那么,RTR(R的转置乘以R)就是共词矩阵(这里假定R中只有0和1两个值表示是否出现这个词,我们下面的计算所用的不只是1,而是>=1的数值表示词频,原理一样)。如果先把R去中心化得到矩阵B(转换成mean deviation form),那么,BTB(B的转置乘以B)就是协方差矩阵。 covariance = np.cov(array_word_frequence_matrix, rowvar = False) covariance
输出结果如下: array([[ 2.46042976e+01, 6.18038032e+00, 3.36027827e+00, ..., 1.93754805e-01, 1.44304255e-01, 1.33315244e-01], [ 6.18038032e+00, 5.52577669e+00, 1.20447814e+00, ..., 4.80938814e-02, 2.74894858e-02, 5.63356397e-02], [ 3.36027827e+00, 1.20447814e+00, 5.66615038e+00, ..., 1.27583322e-02, 4.51657396e-03, -5.09881065e-03], ..., [ 1.93754805e-01, 4.80938814e-02, 1.27583322e-02, ..., 4.28707095e-02, 3.03554470e-03, 5.78279745e-03], [ 1.44304255e-01, 2.74894858e-02, 4.51657396e-03, ..., 3.03554470e-03, 8.40795007e-02, -1.08533442e-03], [ 1.33315244e-01, 5.63356397e-02, -5.09881065e-03, ..., 5.78279745e-03, -1.08533442e-03, 7.03432370e-02]])
协方差矩阵是一个对称矩阵,对角线上的值是每个词的方差(variance),为了画图的时候不画环回的边,我们把对角线的所有值赋0 np.fill_diagonal(covariance, 0) covariance
输出结果如下: array([[ 0.00000000e+00, 6.18038032e+00, 3.36027827e+00, ..., 1.93754805e-01, 1.44304255e-01, 1.33315244e-01], [ 6.18038032e+00, 0.00000000e+00, 1.20447814e+00, ..., 4.80938814e-02, 2.74894858e-02, 5.63356397e-02], [ 3.36027827e+00, 1.20447814e+00, 0.00000000e+00, ..., 1.27583322e-02, 4.51657396e-03, -5.09881065e-03], ..., [ 1.93754805e-01, 4.80938814e-02, 1.27583322e-02, ..., 0.00000000e+00, 3.03554470e-03, 5.78279745e-03], [ 1.44304255e-01, 2.74894858e-02, 4.51657396e-03, ..., 3.03554470e-03, 0.00000000e+00, -1.08533442e-03], [ 1.33315244e-01, 5.63356397e-02, -5.09881065e-03, ..., 5.78279745e-03, -1.08533442e-03, 0.00000000e+00]])
8 生成图并进行探索 8.1 从NumPy数组生成networkx图 参看networkx文档,有专门的函数从其他数据结构直接生成graph graph_covariance = nx.from_numpy_array(covariance) print(nx.info(graph_covariance)) #graph_covariance.edges(data=True)
输出结果如下: Name: Type: Graph Number of nodes: 133 Number of edges: 8778 Average degree: 132.0000
8.2 给node加上label 对程序代码的解释参看《用networkx和python编程可视化分析共词关系图》,不再赘述。 coword_labels = {} for idx, node in enumerate(graph_covariance.nodes()): print("idx=", idx, "; node=", node) coword_labels[node] = coword_names[idx] graph_covariance = nx.relabel_nodes(graph_covariance, coword_labels) sorted(graph_covariance)

8.3 画图 figure函数的使用方法参看pyplot官网 。其他参考资料: 由于是一个全连接图,就没有画的必要了,下面的代码都注释掉了。 #pos = nx.spring_layout(graph_covariance) #plt.figure(1,figsize=(120,120)) #nx.draw(graph_covariance, pos, node_size=10, with_labels=True, font_size=22, font_color="red") #plt.show()
9 用MST(maximum spanning tree)删减边 9.1 MST计算 graph_covariance_mst = nx.maximum_spanning_tree(graph_covariance) print(nx.info(graph_covariance_mst)) # graph_covariance_mst.edges(data=True)
输出结果如下: Name: Type: Graph Number of nodes: 133 Number of edges: 132 Average degree: 1.9850
9.2 画MST后的图 # 方案2: #pos = nx.circular_layout(graph_covariance_mst) pos = nx.spring_layout(graph_covariance_mst) plt.figure(2,figsize=(30,30)) nx.draw(graph_covariance_mst, pos, node_size=50, with_labels=True, font_size=22, font_color="red") plt.show()

10 设定阈值删减边 10.1 选择阈值 删掉多少边比较好呢?我们先看看这些位置上的边权重是多少: coword_median = np.median(covariance) coword_median
输出结果:0.006647673314339978 coword_max = np.max(covariance) coword_max
输出结果:6.180380319269207 coword_min = np.min(covariance) coword_min
输出结果:-0.10413934488008564 coword_per10 = np.percentile(covariance, 90) coword_per10
输出结果:0.08054274257977977 coword_per2 = np.percentile(covariance, 98) coword_per2
输出结果:0.37216373475632675 10.2 删除权重小于2%分位的边 我们不挨个尝试删减度了,直接实验重度删减后的效果 graph_covariance_per2 = graph_covariance.copy() graph_covariance_per2.remove_edges_from([(n1, n2) for n1, n2, w in graph_covariance_per2.edges(data="weight") if w < coword_per2]) pos = nx.spring_layout(graph_covariance_per2) plt.figure(1,figsize=(30,30)) nx.draw(graph_covariance_per2, pos, node_size=10, with_labels=True, font_size=22, font_color="red") plt.show()

10.3 删除基于2%分位裁剪的图的孤立点 graph_covariance_per2.remove_nodes_from(list(nx.isolates(graph_covariance_per2))) #pos = nx.circular_layout(graph_covariance_per2) pos = nx.spring_layout(graph_covariance_per2) plt.figure(1,figsize=(20,20)) nx.draw(graph_covariance_per2, pos, node_size=10, with_labels=True, font_size=22, font_color="blue") plt.show()

11 点度中心性分析 11.1 定义一个公共画图函数 下面的代码来自NetworkX的中心性分析案例:plot_degree.html。将用来从多个角度观察点度中心性。 def diplay_graph_degree(G): seq_degree = sorted((d for n, d in G.degree()), reverse=True) dmax = max(seq_degree) fig = plt.figure("Degree of the count graph", figsize=(8, 8)) # Create a gridspec for adding subplots of different sizes axgrid = fig.add_gridspec(5, 4) ax0 = fig.add_subplot(axgrid[0:3, :]) Gcc = G.subgraph(sorted(nx.connected_components(G), key=len, reverse=True)[0]) pos = nx.spring_layout(Gcc, seed=10396953) nx.draw_networkx_nodes(Gcc, pos, ax=ax0, node_size=20) nx.draw_networkx_edges(Gcc, pos, ax=ax0, alpha=0.4) ax0.set_title("Connected components of G") ax0.set_axis_off() ax1 = fig.add_subplot(axgrid[3:, :2]) ax1.plot(seq_degree, "b-", marker="o") ax1.set_title("Degree Rank Plot") ax1.set_ylabel("Degree") ax1.set_xlabel("Rank") ax2 = fig.add_subplot(axgrid[3:, 2:]) ax2.bar(*np.unique(seq_degree, return_counts=True)) ax2.set_title("Degree histogram") ax2.set_xlabel("Degree") ax2.set_ylabel("# of Nodes") fig.tight_layout() plt.show()
11.2 针对MST裁剪的图的处理 11.2.1 对点度中心性排序 sorted(graph_covariance_mst.degree(), key=lambda x: x[1], reverse=True)

11.2.2 综合展示点度中心性 diplay_graph_degree(graph_covariance_mst)

11.3 针对按2%分位数裁剪的图的处理 11.3.1 对点度中心性排序 sorted(graph_covariance_per2.degree(), key=lambda x: x[1], reverse=True)

11.3.2 综合展示点度中心性 diplay_graph_degree(graph_covariance_per2)

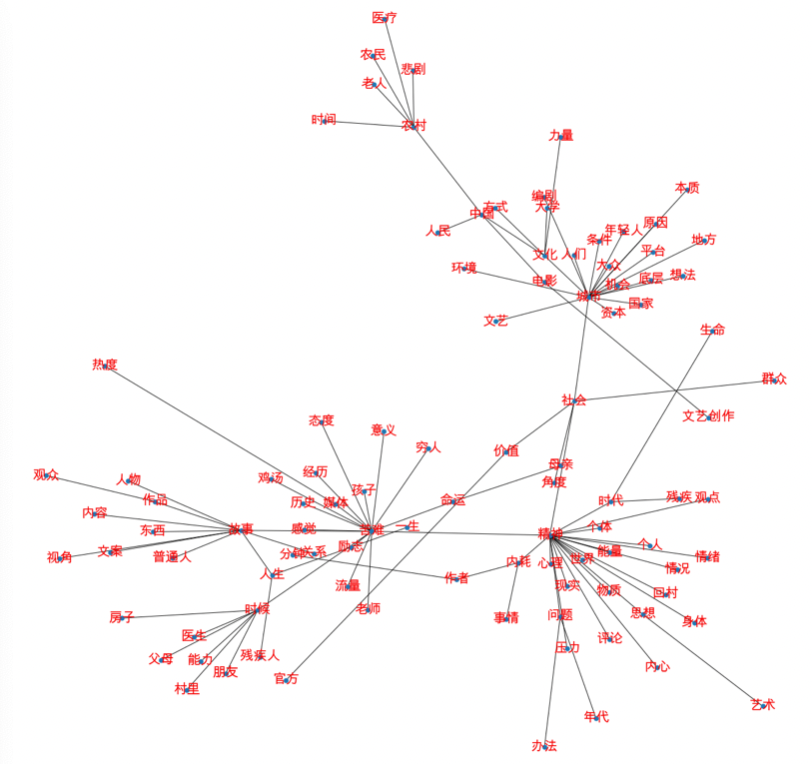
12 总结 12.1 结论 在前面的notebook中,我们使用共词矩阵做社会网络分析和画图,当时比较困扰的一个问题是:“二舅”和“视频”这两个高度集中词形成了绝对的核心,经过MST处理以后,几乎是一个星状结构。计算了协方差以后,有一些改善,但是,又出现了新问题:”彭叔“,”公寓“的文档频率很低,只出现了一次,却被大幅度提升了。 解决这个问题的便捷方法是在GooSeeker分词和情感分析软件上,根据文档频率排序,将普遍词和稀有词都删除,重新导出选词矩阵做实验,就会发现社会网络图的整个拓扑关系都变了,分析结果将极大幅度改善。 
12.2 对比:精选词后协方差图的MST结果 下图可见,有两个中心,一个是“故事-苦难-精神”代表的心理行为,一个是“城市”代表的发展平台。 如果进行MST计算,我个人更倾向于使用协方差矩阵,因为相比共现词矩阵,协方差矩阵更能看到两个词之间有类似出现规律 
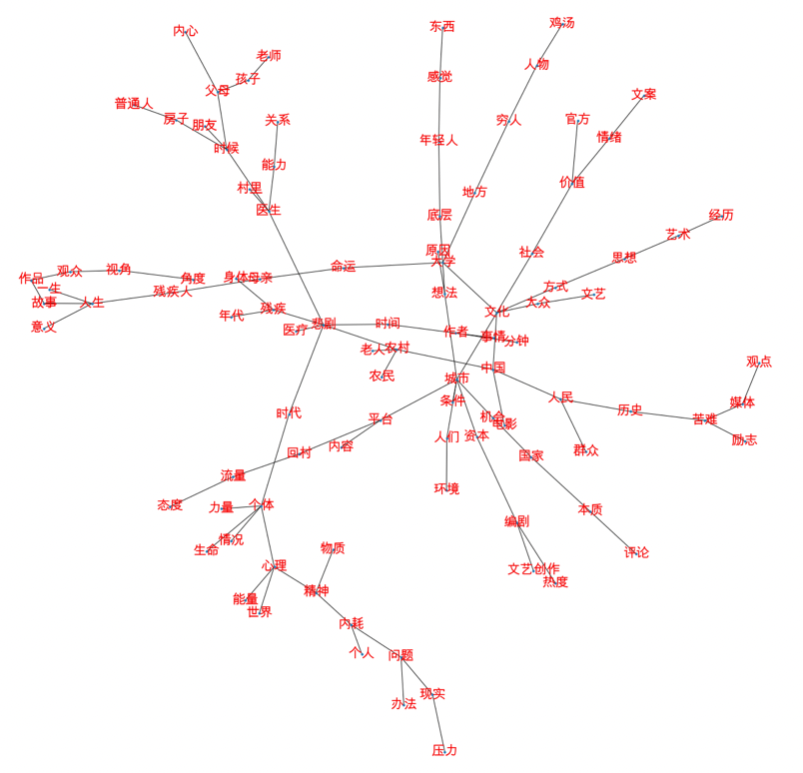
12.3 对比:精选词后皮尔森相关系数图的MST结果 下图可见,MST后很分散,但是还保留了一个中心“城市”代表的发展平台 
13 下载Jupyter Notebook文件 下载notebook源代码文件请进:对共词关系求协方差矩阵后观察社会网络分析效果 |